搜索技巧
海洋云增白
开源地图
AI 搜索答案
沙丘魔堡2
压缩机站
自由职业
policy
小团队
颈挂空调
Chumby
个人电脑
极端主义
团队
PostgreSQL
AI工具
证券
DirectX
DrawingPics
化学
KDE
披萨农场
多动症
植物学
分析化学
Three.js
大会
残疾人学校
初创
QB64
更多
大型语言模型能否改进模拟数据生成? (neurelo.substack.com)
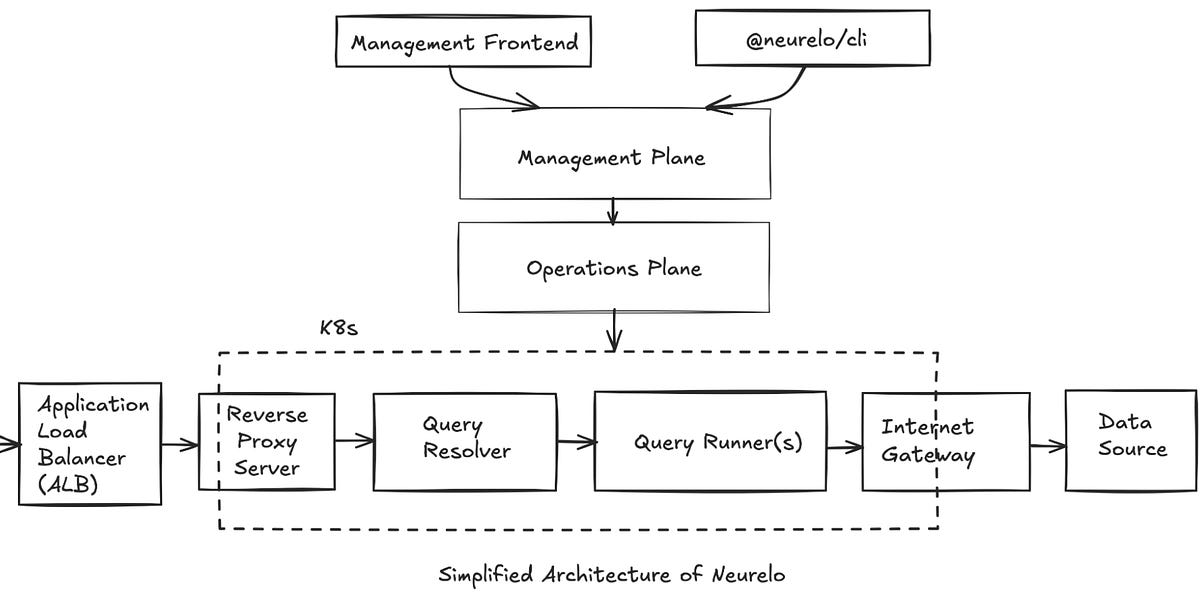
这篇文章探讨了如何利用大型语言模型改进模拟数据的生成。作者首先指出了传统模拟数据生成方法的局限性,然后介绍了他们团队如何利用大型语言模型和拓扑排序算法来生成更逼真、更符合数据库模式的数据。文章详细介绍了他们遇到的挑战,例如处理循环关系、唯一性约束和外键引用等,以及他们如何克服这些挑战。最后,作者展望了模拟数据生成的未来方向,并鼓励读者尝试他们的平台。
评论已经关闭!