Más allá de BPE: El futuro de la tokenización en los grandes modelos de lenguaje
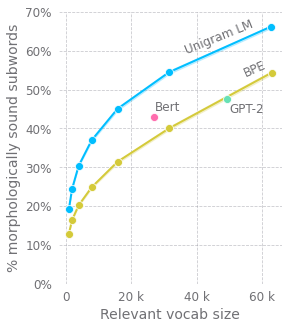
Este artículo explora mejoras en los métodos de tokenización en grandes modelos de lenguaje preentrenados. El autor cuestiona el método comúnmente utilizado de Codificación de Parejas de Bytes (BPE), destacando sus deficiencias en el manejo de subpalabras al principio y dentro de las palabras. Se sugieren alternativas, como agregar una máscara de nueva palabra. Además, el autor argumenta en contra del uso de algoritmos de compresión para el preprocesamiento de entradas, abogando por el modelado de lenguaje a nivel de carácter, trazando paralelos con las Redes Neuronales Recurrentes (RNN) y modelos de autoatención más profundos. Sin embargo, la complejidad cuadrática del mecanismo de atención presenta un desafío. El autor propone un enfoque basado en la estructura de árbol, utilizando subsecuencias con ventana y atención jerárquica para reducir la complejidad computacional mientras se captura mejor la estructura del lenguaje.