Funciones SIMD: La promesa y el peligro de la autovectorización del compilador
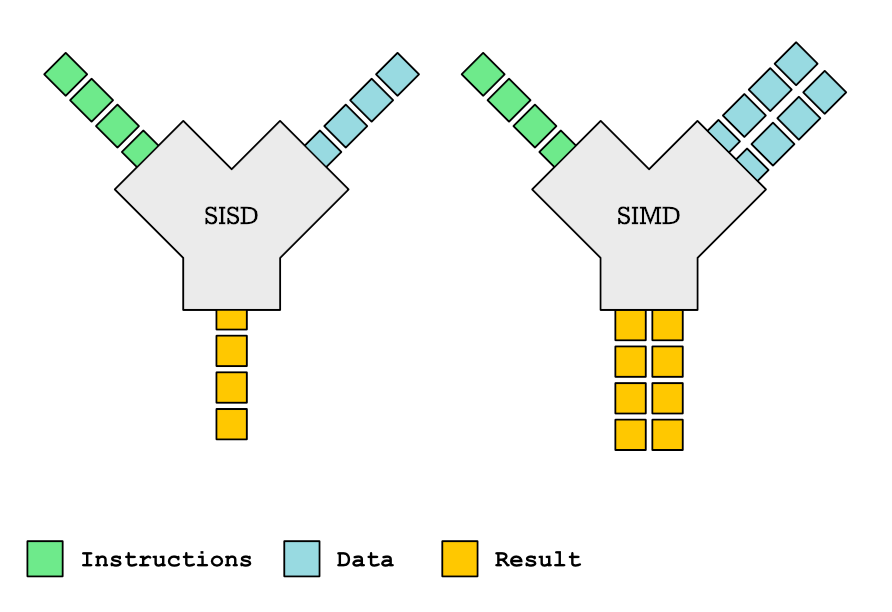
Esta publicación profundiza en las complejidades de las funciones SIMD y su papel en la autovectorización del compilador. Las funciones SIMD, capaces de procesar múltiples puntos de datos simultáneamente, ofrecen mejoras significativas en el rendimiento. Sin embargo, el soporte del compilador para las funciones SIMD es irregular, y el código vectorizado generado puede ser sorprendentemente ineficiente. El artículo detalla cómo declarar y definir funciones SIMD usando pragmas OpenMP y atributos específicos del compilador, analizando el impacto de diferentes tipos de parámetros (variable, uniforme, lineal) en la eficiencia de la vectorización. También abarca el suministro de implementaciones vectorizadas personalizadas usando intrínsecos, el manejo de la inserción de funciones y la navegación por peculiaridades del compilador. Si bien promete ganancias de rendimiento, la aplicación práctica de las funciones SIMD presenta desafíos considerables.
Leer más

