OpenAI lanza gpt-oss: LLMs de peso abierto potentes y ejecutables localmente
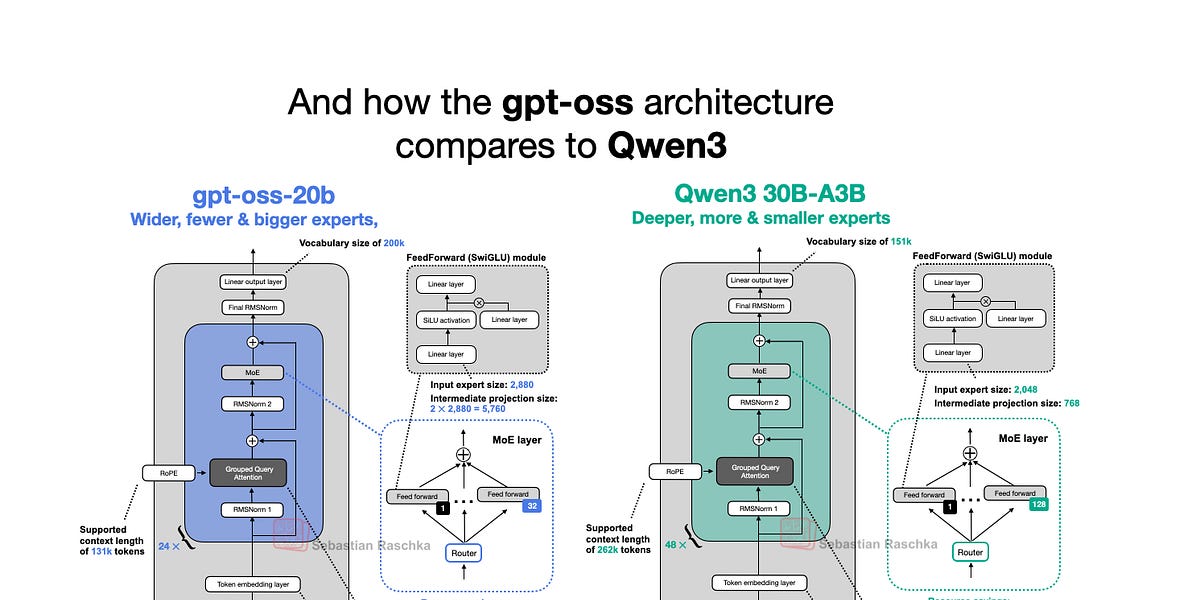
OpenAI lanzó esta semana sus nuevos modelos de lenguaje grandes (LLMs) de peso abierto: gpt-oss-120b y gpt-oss-20b, sus primeros modelos de peso abierto desde GPT-2 en 2019. Sorprendentemente, gracias a optimizaciones inteligentes, pueden ejecutarse localmente. Este artículo profundiza en la arquitectura del modelo gpt-oss, comparándolo con modelos como GPT-2 y Qwen3. Destaca opciones arquitectónicas únicas, como Mixture-of-Experts (MoE), Grouped Query Attention (GQA) y atención con ventana deslizante. Si bien los puntos de referencia muestran que gpt-oss tiene un rendimiento comparable a los modelos de código cerrado en algunas áreas, su capacidad de ejecución local y su naturaleza de código abierto lo convierten en un activo valioso para la investigación y las aplicaciones.
Leer más
