Multiplicación de matrices FP32 optimizada en GPU AMD RDNA3: Superando a rocBLAS en un 60%
2025-03-28
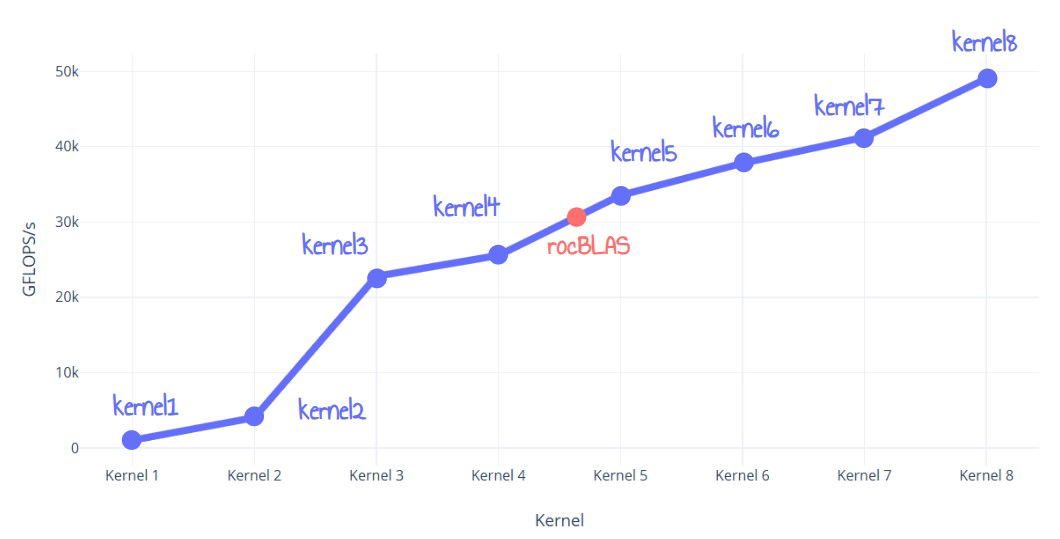
Esta publicación detalla el proceso de optimización para crear un kernel de multiplicación de matrices FP32 para GPUs AMD RDNA3 que supera a rocBLAS en un 60%. El autor refina iterativamente ocho kernels, comenzando con una implementación ingenua y avanzando hacia optimizaciones a nivel de ISA. Las técnicas incluyen el uso de LDS tiling, register tiling, double buffering de memoria global, optimización de la utilización de LDS y, finalmente, optimización de la utilización de VALU a nivel de ISA y desenrollado de bucles. El kernel final supera a rocBLAS, alcanzando casi 50 TFLOPS.
Leer más
Desarrollo
multiplicación de matrices