Mirage Persistent Kernel: Compilando LLMs en un solo megakernel para inferencia ultrarrápida
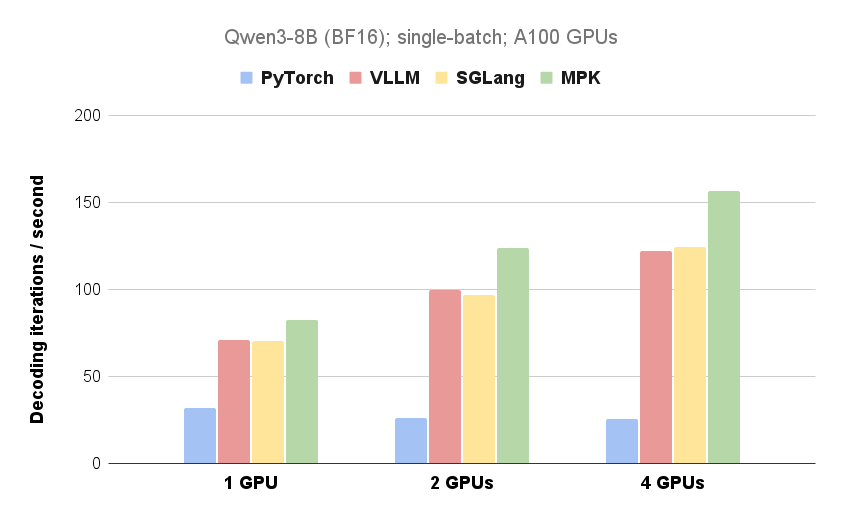
Investigadores de la CMU, UW, Berkeley, NVIDIA y Tsinghua han desarrollado Mirage Persistent Kernel (MPK), un compilador y sistema de ejecución que transforma automáticamente la inferencia de modelos de lenguaje grandes (LLMs) en múltiples GPUs en un megakernel de alto rendimiento. Al fusionar toda la computación y comunicación en un solo kernel, MPK elimina la sobrecarga de lanzamiento del kernel, superpone la computación y la comunicación y reduce significativamente la latencia de inferencia del LLM. Los experimentos demuestran mejoras de rendimiento sustanciales en configuraciones de GPU única y múltiple, con ganancias más pronunciadas en entornos de múltiples GPUs. El trabajo futuro se centra en ampliar MPK para admitir arquitecturas de GPU de próxima generación y manejar cargas de trabajo dinámicas.
Leer más