Alineando características polinomial con la distribución de datos: El problema de atención-alineación en ML
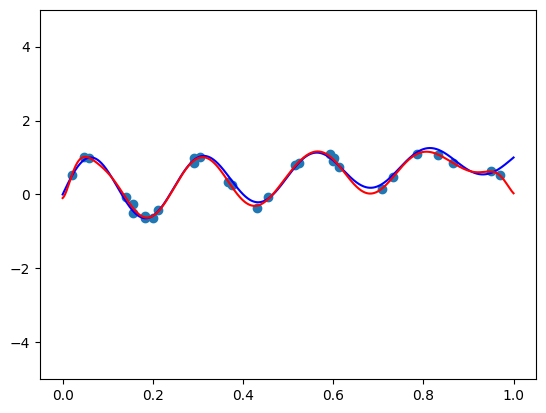
Esta publicación explora la alineación de características polinomiales con la distribución de datos para mejorar el rendimiento del modelo de aprendizaje automático. Las bases ortogonales producen características informativas cuando los datos se distribuyen uniformemente, pero los datos del mundo real no lo están. Se presentan dos enfoques: un truco de mapeo, que transforma los datos en una distribución uniforme antes de aplicar una base ortogonal; y la multiplicación por una función cuidadosamente seleccionada para ajustar la función de peso de la base ortogonal para que se alinee con la distribución de datos. La primera es más práctica, alcanzable con el QuantileTransformer de Scikit-Learn. La segunda es más compleja, requiriendo un conocimiento matemático más profundo y ajustes finos. Los experimentos en el conjunto de datos de viviendas de California muestran que las características casi ortogonales del primer método superan el escalado mínimo-máximo tradicional en la regresión lineal.
Leer más