Mirage Persistent Kernel: Compiling LLMs into a Single Megakernel for Blazing-Fast Inference
2025-06-19
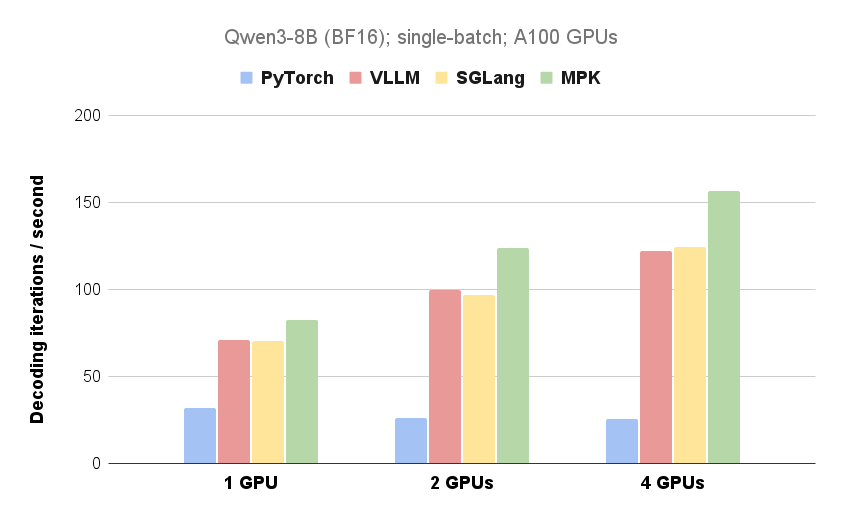
Researchers from CMU, UW, Berkeley, NVIDIA, and Tsinghua have developed Mirage Persistent Kernel (MPK), a compiler and runtime system that automatically transforms multi-GPU large language model (LLM) inference into a high-performance megakernel. By fusing all computation and communication into a single kernel, MPK eliminates kernel launch overhead, overlaps computation and communication, and significantly reduces LLM inference latency. Experiments demonstrate substantial performance improvements on both single- and multi-GPU configurations, with more pronounced gains in multi-GPU settings. Future work focuses on extending MPK to support next-generation GPU architectures and handle dynamic workloads.
AI
megakernel