Optimizing WMMA Kernels on AMD RDNA 4 Architecture
2025-07-21
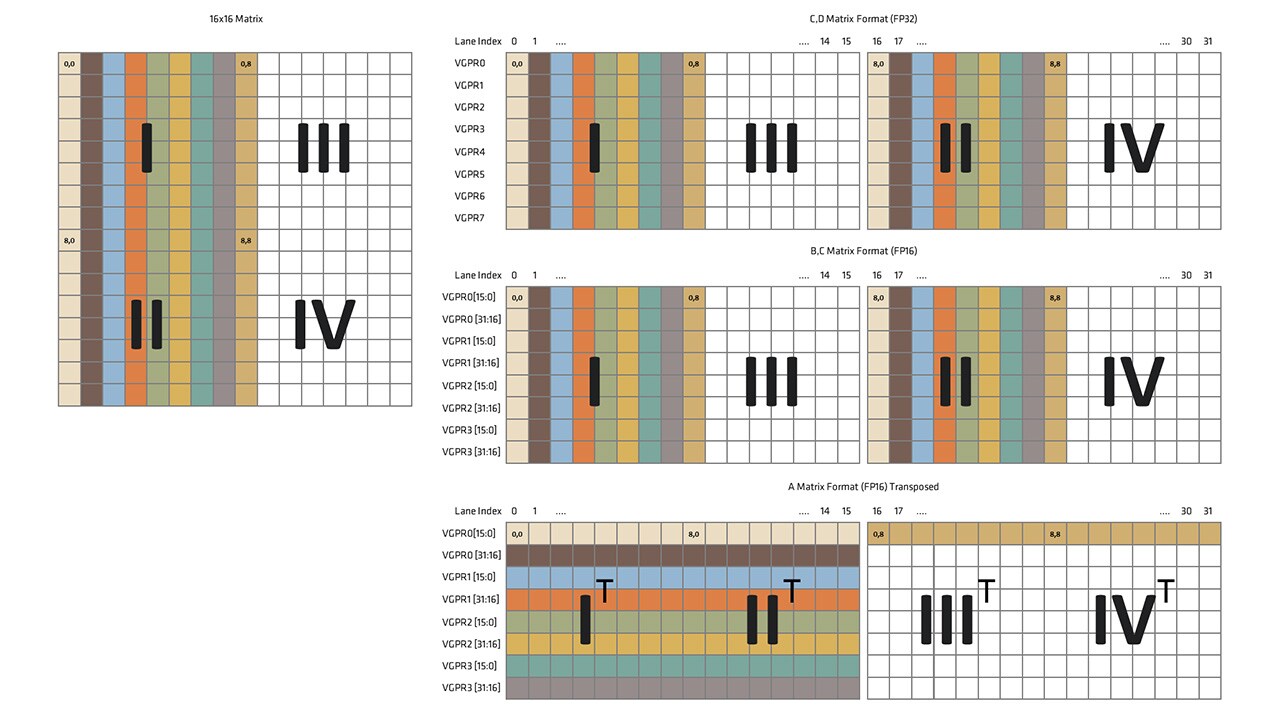
AMD RDNA 4 architecture GPUs, featuring 3rd-generation Matrix Cores, significantly improve Generalized Matrix Multiplication (GEMM) performance. This article delves into optimizing matrix operations using WMMA (Wave Matrix Multiply Accumulate) intrinsics within HIP kernels on RDNA 4 GPUs. It explains WMMA's functionality, the use of new intrinsics like `__builtin_amdgcn_wmma_f32_16x16x16_f16_w32_gfx12`, and key differences from RDNA 3. A simplified Multilayer Perceptron (MLP) implementation example showcases efficient matrix computation on RDNA 4.
Hardware