SIMD Functions: The Promise and Peril of Compiler Auto-Vectorization
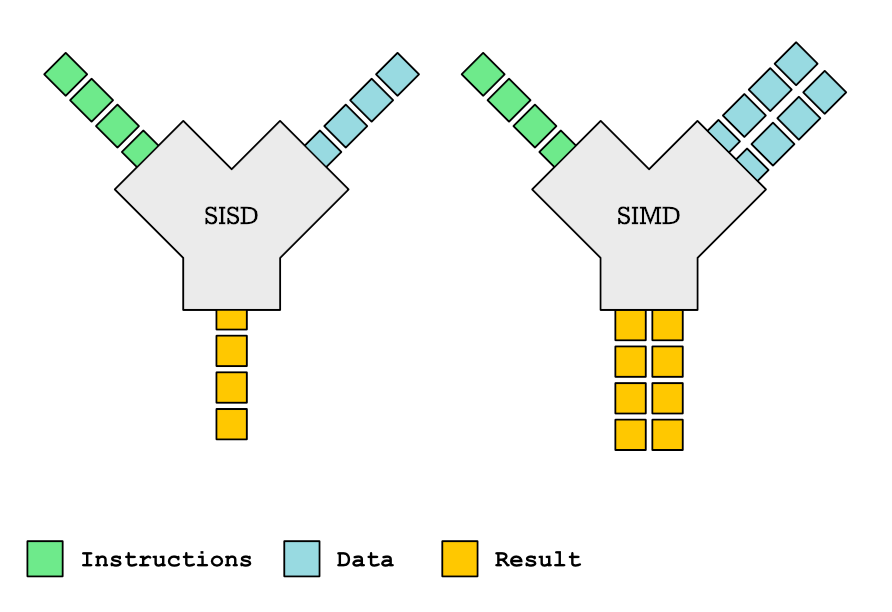
This post delves into the intricacies of SIMD functions and their role in compiler auto-vectorization. SIMD functions, capable of processing multiple data points simultaneously, offer significant performance improvements. However, compiler support for SIMD functions is patchy, and the generated vectorized code can be surprisingly inefficient. The article details how to declare and define SIMD functions using OpenMP pragmas and compiler-specific attributes, analyzing the impact of different parameter types (variable, uniform, linear) on vectorization efficiency. It also covers providing custom vectorized implementations using intrinsics, handling function inlining, and navigating compiler quirks. While promising performance gains, practical application of SIMD functions presents considerable challenges.
Read more

