Five Ways to Model Polymorphic Data in Relational Databases
2025-07-09
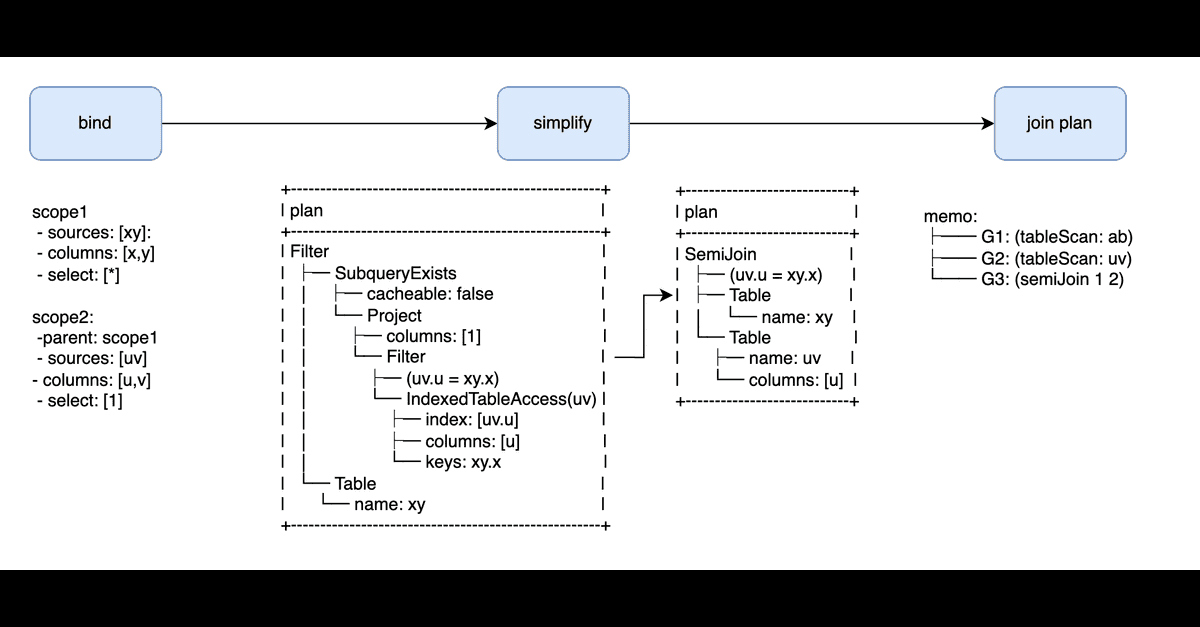
This article explores five approaches to modeling polymorphic data in relational databases: single table, nullable foreign keys, tagged union, child-to-parent foreign keys, and JSON. Each method has its pros and cons; for example, the single table approach is simple but can be slow, while JSON is easily extensible but lacks data validation. The author suggests choosing the method that's easiest to read, maintain, and debug, and avoiding premature optimization.
Read more