Mirage Persistent Kernel: 초고속 추론을 위한 LLM을 단일 메가커널로 컴파일
2025-06-19
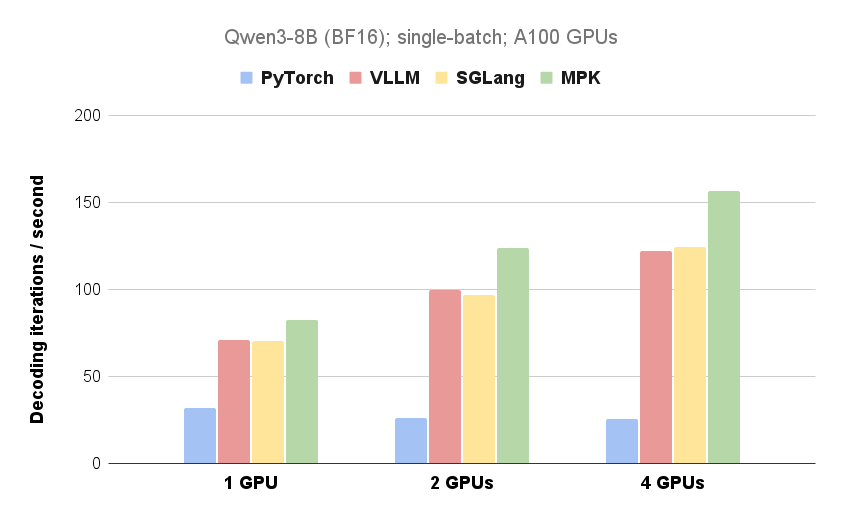
CMU, UW, 버클리, NVIDIA, 칭화대 연구원들은 Mirage Persistent Kernel(MPK)을 개발했습니다. 이는 멀티 GPU 대규모 언어 모델(LLM) 추론을 고성능 메가커널로 자동 변환하는 컴파일러 및 런타임 시스템입니다. 모든 계산과 통신을 단일 커널로 통합하여 MPK는 커널 시작 오버헤드를 제거하고 계산과 통신을 오버랩하여 LLM 추론 지연 시간을 크게 줄입니다. 실험 결과 단일 GPU와 멀티 GPU 구성 모두에서 상당한 성능 향상을 보여주었으며, 특히 멀티 GPU 환경에서 그 이점이 더욱 두드러집니다. 향후 연구는 차세대 GPU 아키텍처 지원과 동적 워크로드 처리에 중점을 둘 것입니다.
AI
메가커널