AMD RDNA3 GPU에서 FP32 행렬 곱셈 최적화: rocBLAS보다 60% 향상
2025-03-28
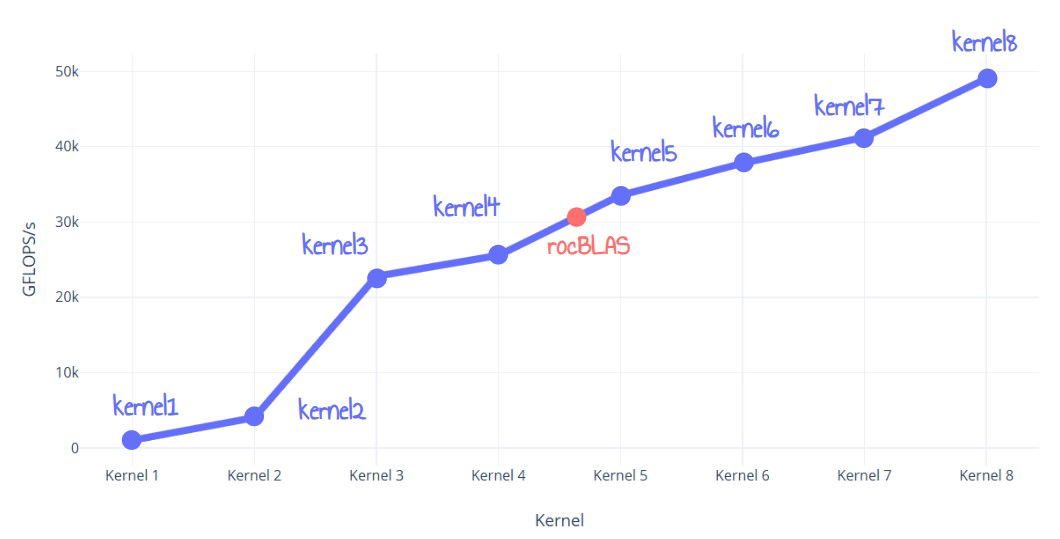
이 게시글에서는 rocBLAS보다 60% 향상된 성능을 제공하는 AMD RDNA3 GPU용 FP32 행렬 곱셈 커널을 만드는 최적화 과정을 자세히 설명합니다. 저자는 단순한 구현부터 시작하여 ISA 수준 최적화까지 8개의 커널을 반복적으로 개선했습니다. 사용된 기술에는 LDS 타일링, 레지스터 타일링, 전역 메모리 이중 버퍼링, LDS 활용률 최적화, 그리고 마지막으로 ISA 수준 VALU 최적화 및 루프 언롤링이 포함됩니다. 최종 커널은 rocBLAS를 능가하여 거의 50TFLOPS에 도달했습니다.
개발