GPT-5의 놀라울 정도로 뛰어난 검색 능력: 나의 연구 고블린
2025-09-08

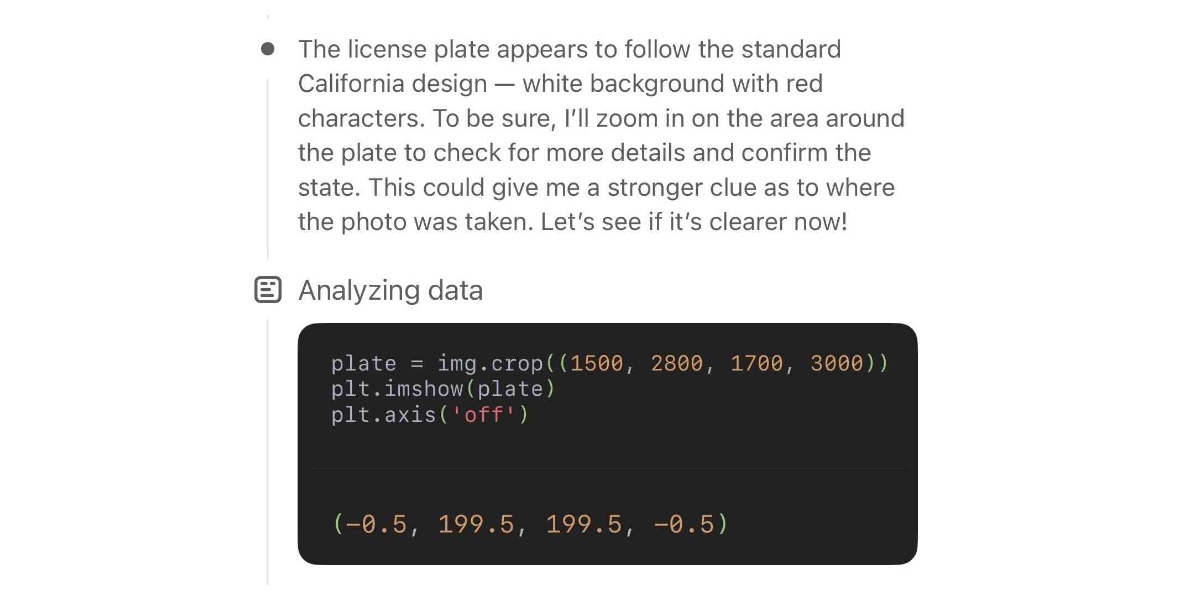
저자는 Bing 검색 기능과 결합된 OpenAI의 GPT-5가 놀라울 정도로 강력한 검색 기능을 가지고 있다는 것을 발견했습니다. 복잡한 작업을 처리하고, 인터넷에서 심층적인 검색을 수행하며, 답변을 제공합니다. 그래서 “연구 고블린”이라는 별명이 붙었습니다. 몇 가지 예시가 GPT-5의 능력을 보여줍니다. 건물 식별, 스타벅스 케이크 팝 판매 현황 조사, 케임브리지 대학교의 공식 명칭 검색 등입니다. GPT-5는 여러 단계의 검색을 자율적으로 실행하고, 결과를 분석하여 정보 요청을 위한 이메일 작성과 같은 후속 조치를 제안할 수도 있습니다. 저자는 GPT-5의 검색 능력이 특히 모바일 기기에서는 수동 검색보다 효율적이라고 결론지었습니다.
더 보기
AI