OpenAI تطلق نماذج gpt-oss: نماذج لغوية ضخمة مفتوحة الوزن وقوية قابلة للتشغيل محليًا
2025-08-10
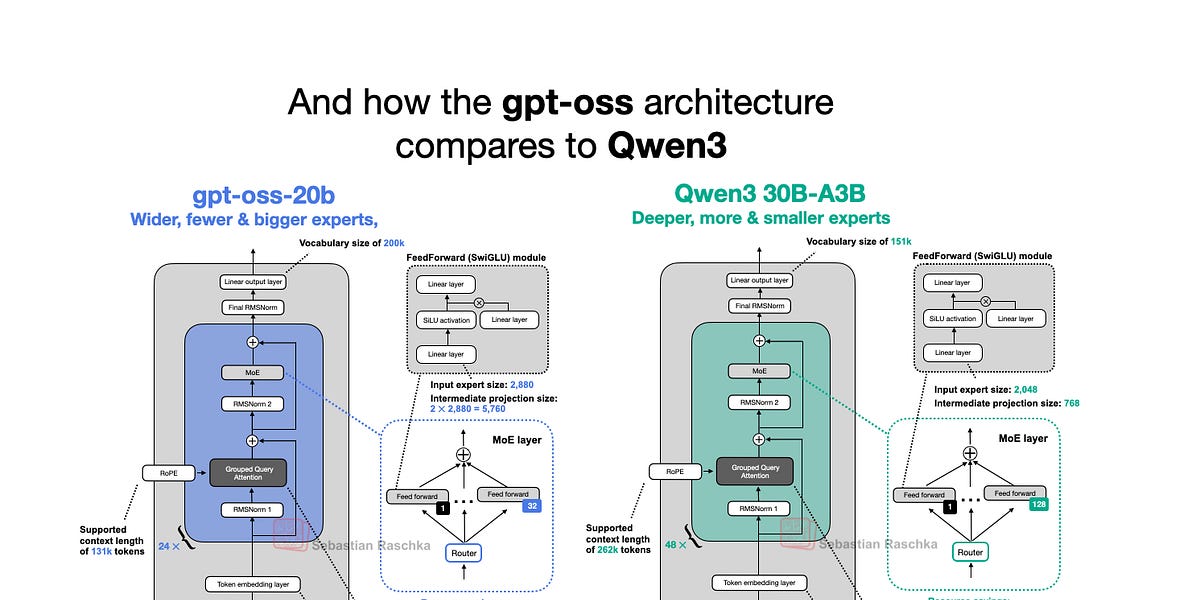
أصدرت OpenAI هذا الأسبوع نماذجها اللغوية الكبيرة الجديدة ذات الوزن المفتوح: gpt-oss-120b و gpt-oss-20b، وهما أول نموذجين لها مفتوحي الوزن منذ GPT-2 في عام 2019. والمثير للدهشة، بفضل التحسينات الذكية، يمكن تشغيلهما محليًا. تتعمق هذه المقالة في بنية نموذج gpt-oss، وتقارنه بنماذج مثل GPT-2 و Qwen3. وتسلط الضوء على خيارات البنية الفريدة، مثل خليط الخبراء (MoE)، والانتباه للاستعلامات المجمعة (GQA)، وانتباه النافذة المنزلقة. وعلى الرغم من أن معايير الأداء تُظهر أن gpt-oss يُقدم أداءً مُقارِباً للنماذج الخاصة في بعض المجالات، إلا أن إمكانية تشغيله محليًا وطبيعته مفتوحة المصدر تجعله موردًا قيِّمًا للبحث والتطبيقات.
اقرأ المزيد
الذكاء الاصطناعي
وزن مفتوح

