다항식 특징과 데이터 분포의 정렬: ML에서의 어텐션-정렬 문제
2025-08-26
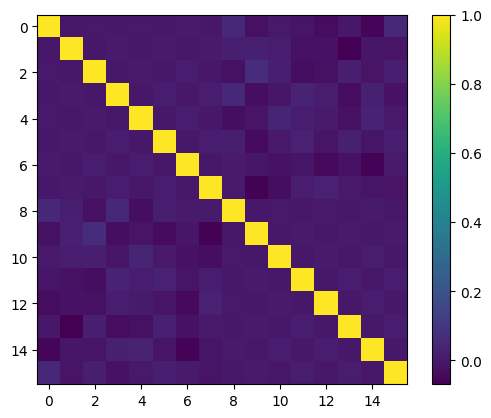
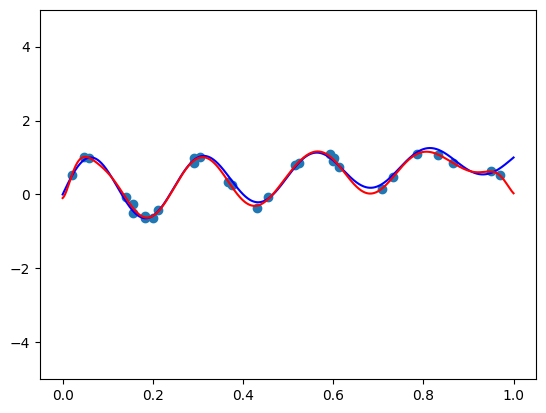
이 글에서는 기계 학습 모델 성능 향상을 위해 다항식 특징과 데이터 분포의 정렬을 탐구합니다. 직교 기저는 데이터가 균일하게 분포되어 있을 때 정보량이 많은 특징을 생성하지만, 실제 데이터는 그렇지 않습니다. 두 가지 접근 방식이 제시됩니다. 하나는 직교 기저를 적용하기 전에 데이터를 균일 분포로 변환하는 매핑 기법입니다. 다른 하나는 신중하게 선택된 함수를 곱하여 직교 기저의 가중치 함수를 조정하여 데이터 분포에 맞추는 것입니다. 전자는 Scikit-Learn의 QuantileTransformer로 구현할 수 있는, 보다 실용적인 방법입니다. 후자는 더 복잡하며, 심오한 수학적 이해와 미세 조정이 필요합니다. 캘리포니아 주택 데이터 세트 실험에서 전자의 방법으로 생성된 준 직교 특징량이 기존의 최소-최대 스케일링보다 선형 회귀에서 더 우수한 성능을 보였습니다.
더 보기