BPE를 넘어: 대규모 언어 모델에서 토큰화의 미래
2025-05-30
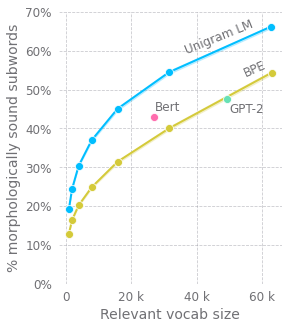
본 논문은 대규모 사전 훈련된 언어 모델에서 토큰화 방법의 개선에 대해 탐구합니다. 저자는 일반적으로 사용되는 바이트 쌍 인코딩(BPE) 방법의 문제점을 지적하고, 단어의 시작과 내부에서의 하위 단어 처리의 결함을 강조합니다. 새로운 단어 마스크를 추가하는 등의 대안이 제시됩니다. 또한 저자는 입력 전처리에 압축 알고리즘을 사용하는 것에 반대하며, 순환 신경망(RNN) 및 더 깊은 자기 주의 메커니즘 모델과 마찬가지로 문자 수준의 언어 모델링을 제안합니다. 그러나 어텐션 메커니즘의 제곱 복잡도는 과제입니다. 저자는 창문화된 하위 시퀀스와 계층적 어텐션을 사용하여 계산 복잡도를 줄이고 언어 구조를 더 잘 포착하는 트리 구조 기반 접근 방식을 제안합니다.
더 보기
AI