Easily Calculate the Number of Language Model Tokens for a String
2025-02-05
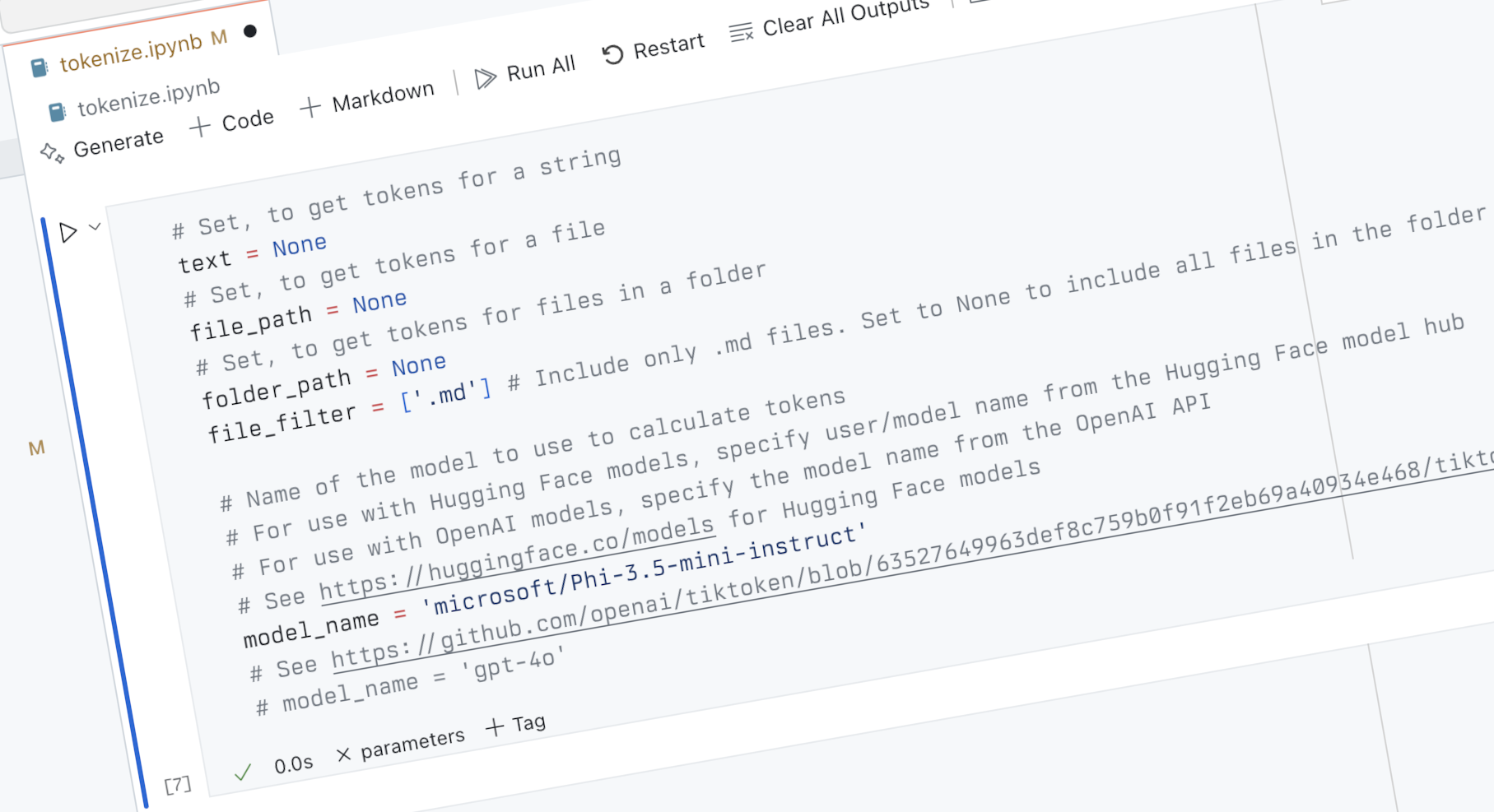
This article presents a simple method to calculate the number of language model tokens in a string. This is crucial for estimating application running costs, checking if text fits within the language model's context window, and determining if chunking is necessary. While a rough estimate can be obtained by dividing the character count by 4, a more accurate method involves using the specific language model (Hugging Face or OpenAI model) you're using. The author provides a Jupyter Notebook to calculate the token count for strings, files, or all files in a folder, eliminating reliance on external services, ensuring security and free usage.
Development
token counting