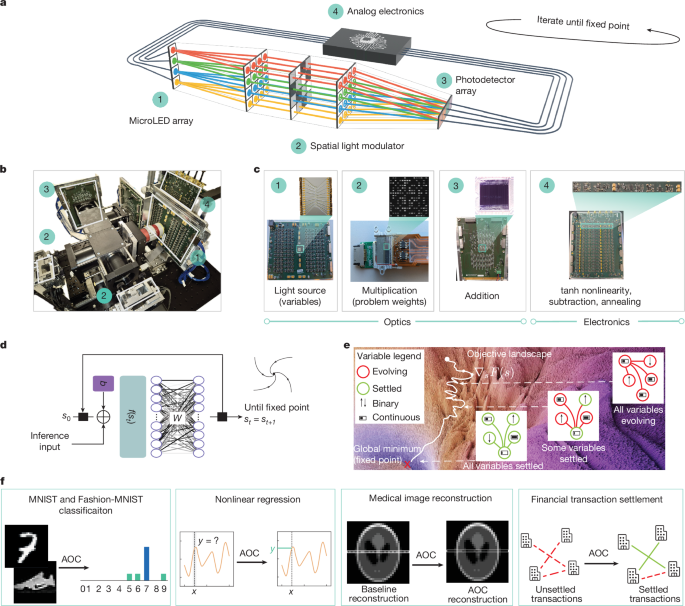
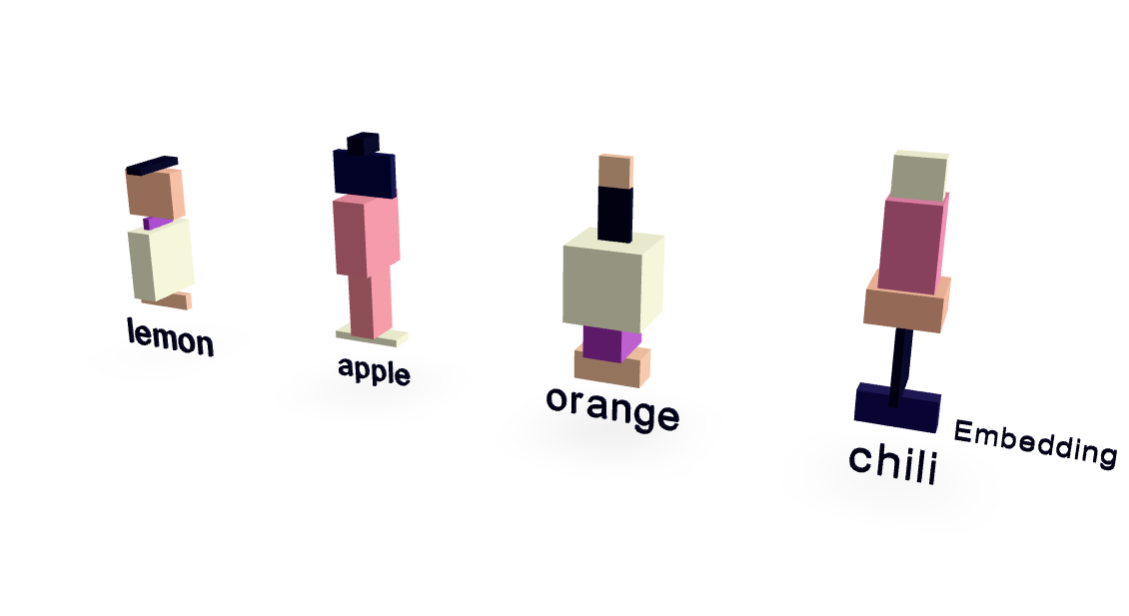
Dimensiones de incrustación: De 300 a 4096 y más allá
Hace unos años, las incrustaciones de 200 a 300 dimensiones eran comunes. Sin embargo, con el auge de los modelos de aprendizaje profundo como BERT y GPT, y los avances en la computación GPU, la dimensionalidad de las incrustaciones ha explotado. Hemos visto una progresión de las 768 dimensiones de BERT a las 1536 de GPT-3 y ahora modelos con 4096 dimensiones o más. Esto se debe a cambios arquitectónicos (Transformadores), conjuntos de datos de entrenamiento más grandes, el auge de plataformas como Hugging Face y los avances en las bases de datos vectoriales. Si bien el aumento de la dimensionalidad ofrece ganancias de rendimiento, también introduce desafíos de almacenamiento e inferencia. Investigaciones recientes exploran representaciones de incrustaciones más eficientes, como el aprendizaje Matryoshka, buscando un mejor equilibrio entre rendimiento y eficiencia.