Multiplication de matrices FP32 optimisée sur GPU AMD RDNA3 : Surpasse rocBLAS de 60 %
2025-03-28
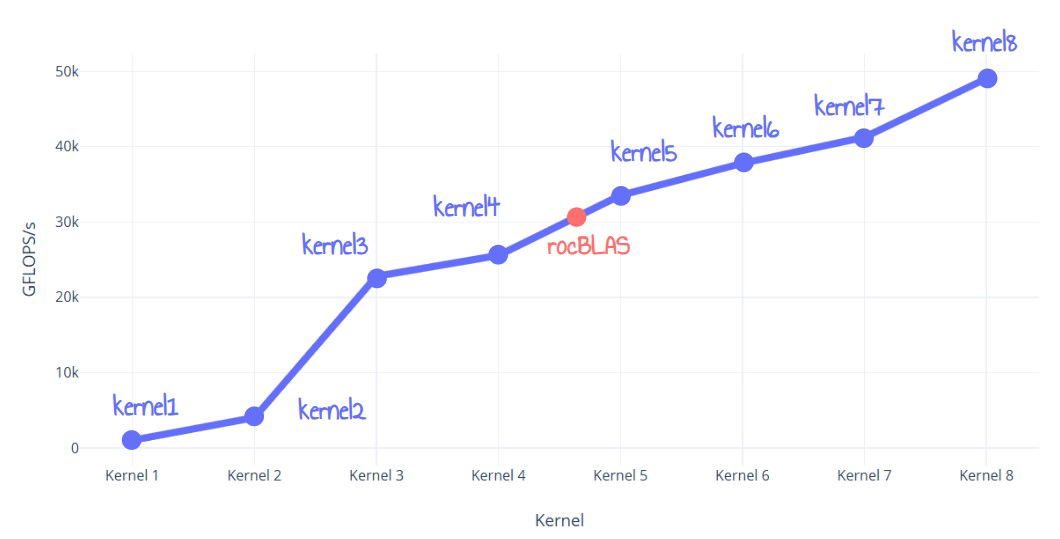
Cet article détaille le processus d’optimisation de la création d’un noyau de multiplication de matrices FP32 pour les GPU AMD RDNA3, surpassant rocBLAS de 60 %. L’auteur affine itérativement huit noyaux, en commençant par une implémentation naïve et en progressant vers des optimisations au niveau de l’ISA. Les techniques incluent le pavage LDS, le pavage des registres, la double mise en mémoire tampon de la mémoire globale, l’optimisation de l’utilisation de LDS et, enfin, l’optimisation de l’utilisation de VALU au niveau de l’ISA et le déroulement des boucles. Le noyau final surpasse rocBLAS, atteignant près de 50 TFLOPS.
Développement
multiplication matricielle