Anthropic corrige trois bugs d'infrastructure affectant Claude
2025-09-18

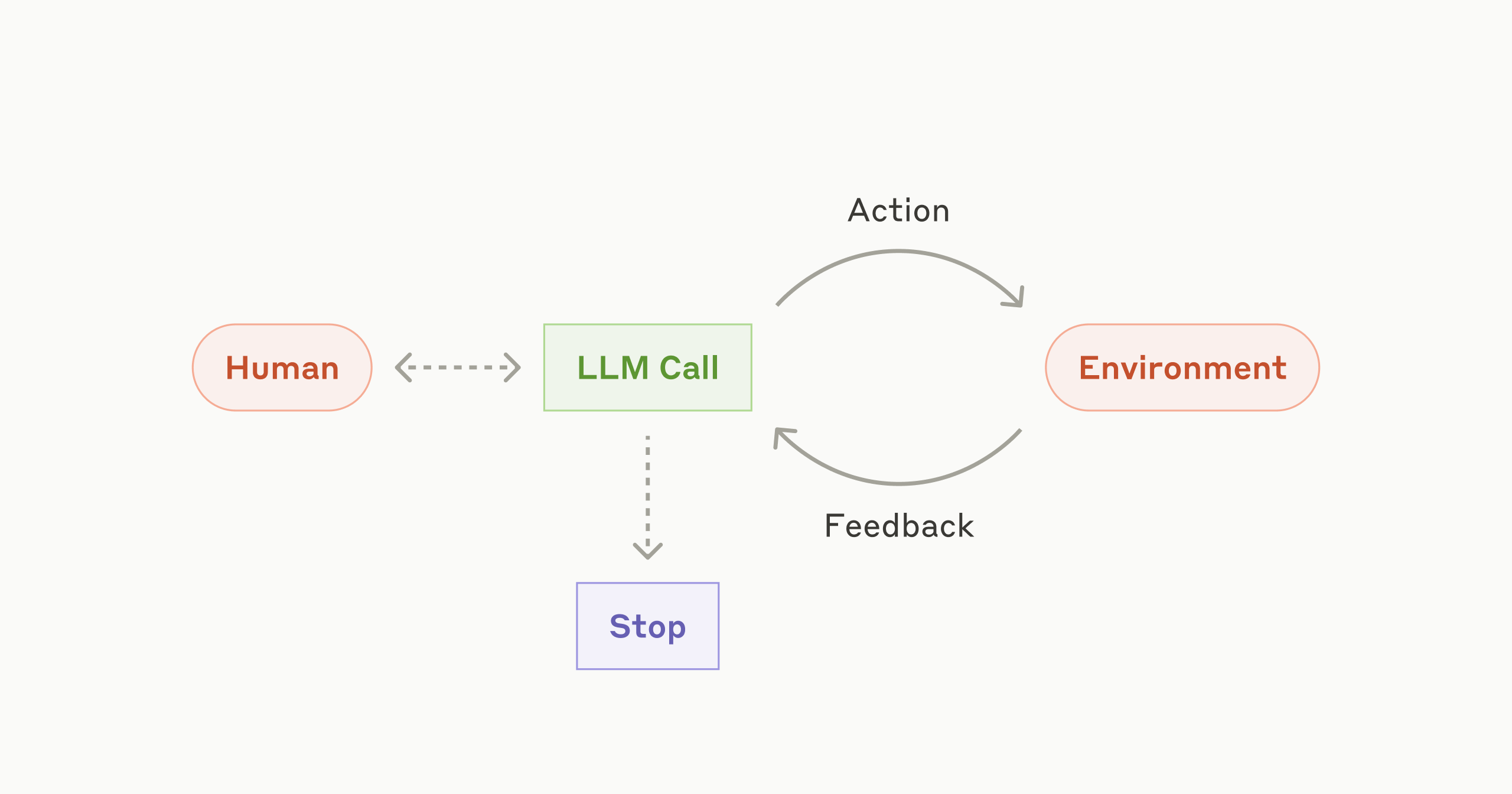
Anthropic a reconnu qu'entre août et début septembre, trois bugs d'infrastructure ont dégradé par intermittence la qualité des réponses de Claude. Ces bugs, causant un mauvais routage des requêtes, une corruption de sortie et des erreurs de compilation, ont affecté un sous-ensemble d'utilisateurs. Anthropic a détaillé les causes, le diagnostic et la résolution de ces bugs, s'engageant à améliorer les outils d'évaluation et de débogage pour éviter toute récurrence. L'incident met en lumière la complexité et les défis de l'infrastructure des modèles de langage de grande taille.
Lire plus