OpenAI、gpt-ossを発表:ローカル実行可能な強力なオープンウェイトLLM
2025-08-10
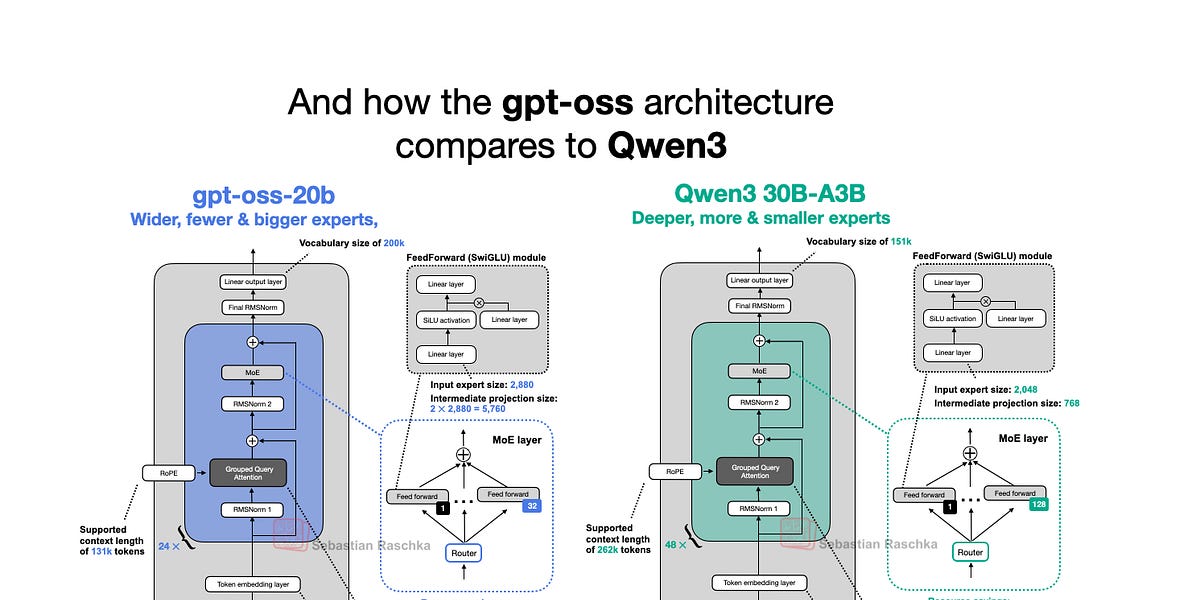
OpenAIは今週、2019年のGPT-2以来となる初のオープンウェイトモデルであるgpt-oss-120bとgpt-oss-20bをリリースしました。驚くべきことに、巧妙な最適化により、ローカルで実行できます。この記事では、gpt-ossモデルのアーキテクチャを詳しく掘り下げ、GPT-2やQwen3などのモデルと比較します。Mixture-of-Experts(MoE)、Grouped Query Attention(GQA)、スライドウィンドウアテンションなどの独自のアーキテクチャ上の選択を強調しています。ベンチマークでは、gpt-ossはいくつかの分野でクローズドソースモデルと同等の性能を示していますが、ローカル実行可能性とオープンソースの性質により、研究やアプリケーションにとって貴重な資産となります。
続きを読む
AI
オープンウェイト

