SIMD 함수: 컴파일러 자동 벡터화의 장점과 위험
2025-07-05
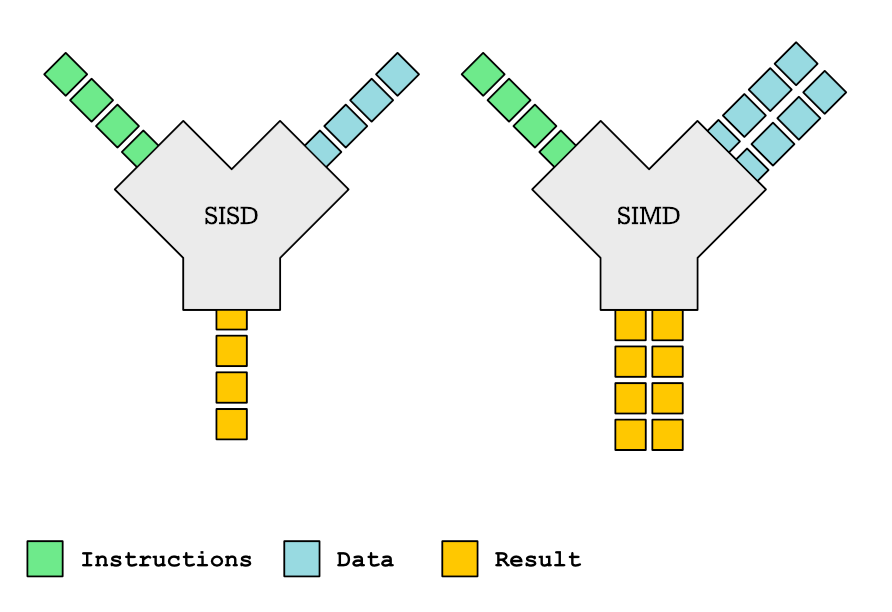
이 글에서는 SIMD 함수와 컴파일러 자동 벡터화에서의 역할에 대해 자세히 설명합니다. 여러 데이터 포인트를 동시에 처리할 수 있는 SIMD 함수는 성능을 크게 향상시킬 수 있습니다. 그러나 컴파일러의 SIMD 함수 지원은 불균일하며 생성된 벡터화 코드는 놀라울 정도로 비효율적일 수 있습니다. 이 글에서는 OpenMP pragma와 컴파일러 특정 속성을 사용하여 SIMD 함수를 선언 및 정의하는 방법을 자세히 설명하고 다양한 매개변수 유형(변수, 균일, 선형)이 벡터화 효율에 미치는 영향을 분석합니다. 또한 함수 인라이닝 처리 및 컴파일러의 특성을 다루는 방법에 대해서도 설명합니다. 성능 향상이라는 큰 가능성을 가지고 있지만 SIMD 함수의 실제 적용에는 상당한 어려움이 있습니다.
더 보기
개발


