Scale Beats All: AI Agent Achieves SOTA on swebench-verified
2025-01-08
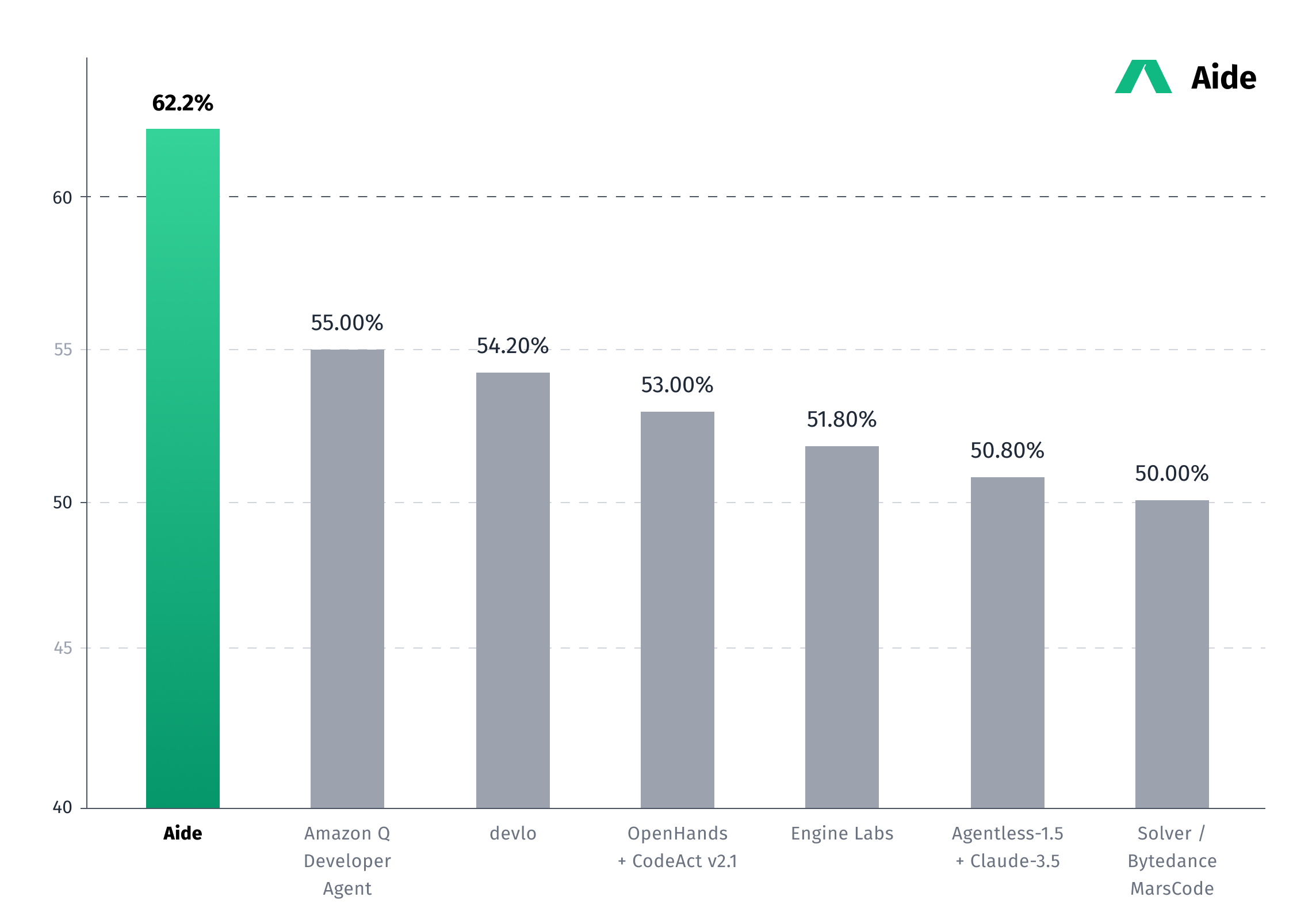
CodeStory achieved state-of-the-art results on the swebench-verified benchmark, resolving 62.2% of issues by leveraging massive test-time inference. They used Sonnet 3.5 LLM and a simple toolset, abandoning an initial MCTS framework in favor of scaling. By running numerous agents across multiple VMs and Anthropic accounts, they demonstrated the power of scale in solving complex software engineering problems, even for small teams. This reinforces the 'bitter lesson' that scale trumps all, offering a new paradigm for AI in software engineering.
(aide.dev)
Development