扩散强制:下一词预测与全序列扩散的结合
2024-07-04
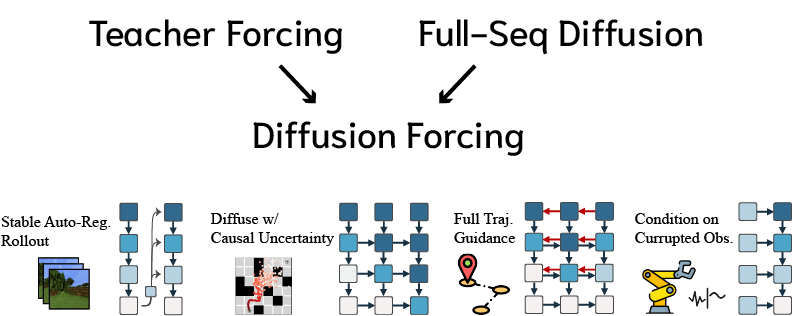
本文介绍了一种新的训练范式“扩散强制”,它训练扩散模型对具有一致逐词噪声水平的词符集进行去噪。该方法将扩散强制应用于序列生成建模,通过训练因果下一词预测模型来生成一个或多个未来词符,而无需完全扩散过去的词符。实验证明,这种方法结合了下一词预测模型(如可变长度生成)和全序列扩散模型(如将采样引导至期望轨迹的能力)的优点。
73