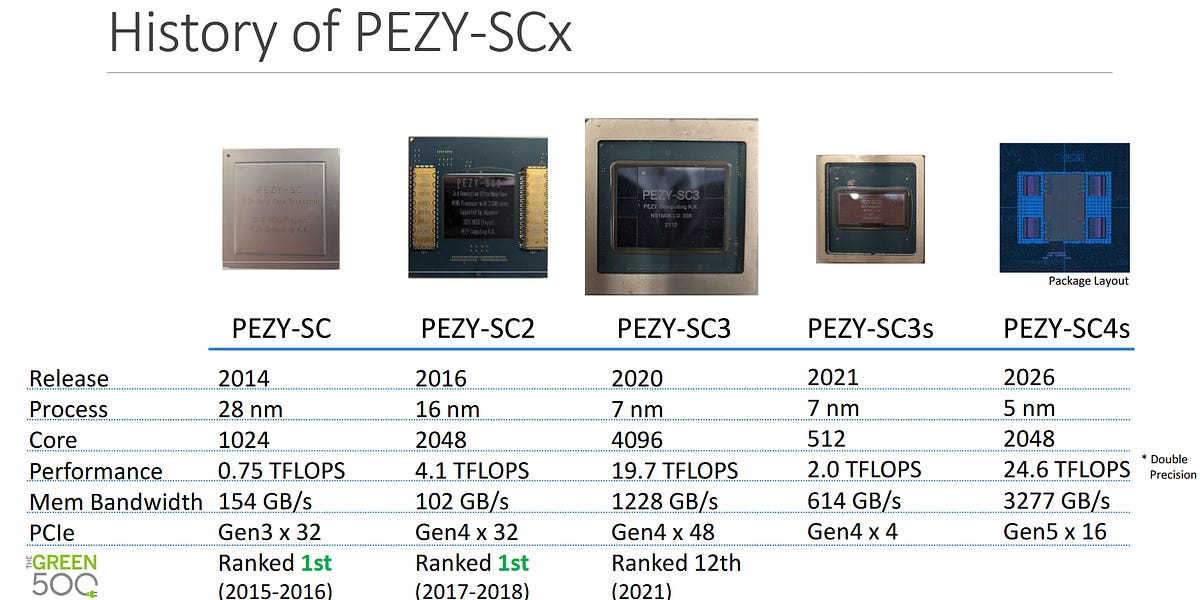
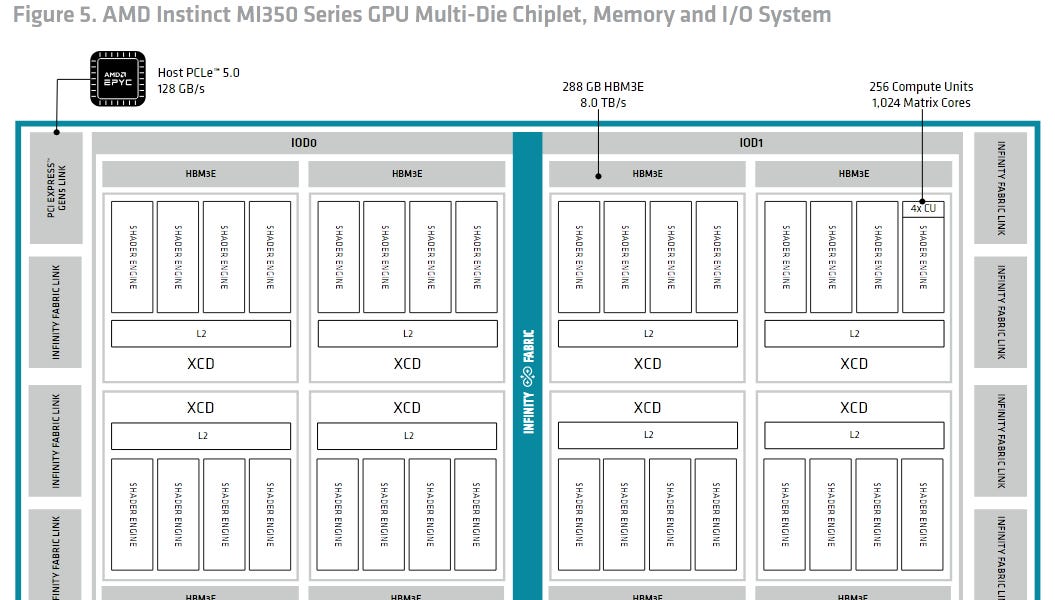
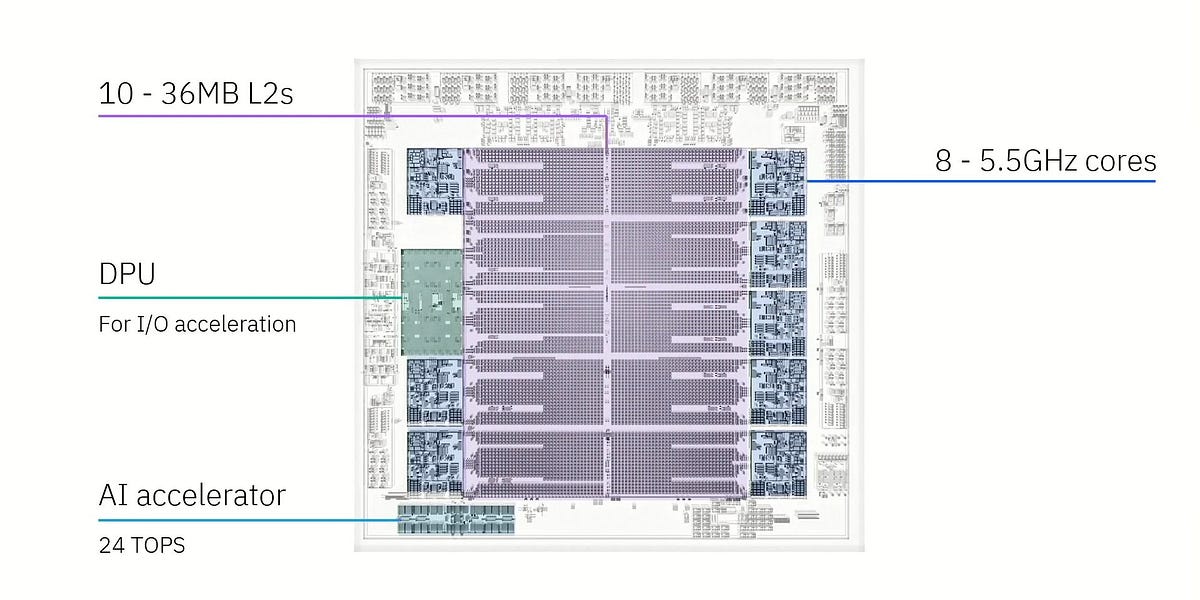
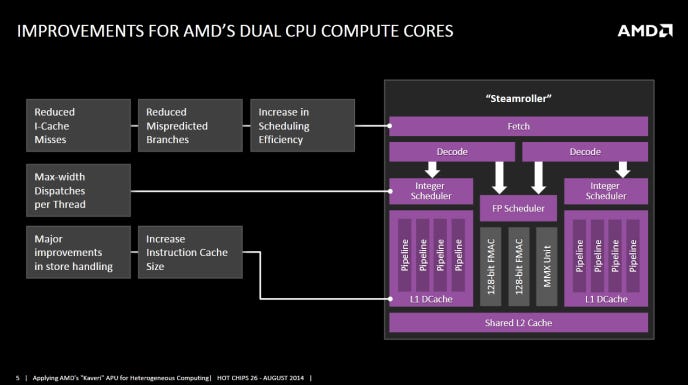
AMD RDNA4: Efficiency Reigns Supreme in New GPU Architecture

AMD's latest RDNA4 architecture prioritizes efficiency over raw performance. The RX 9000 series GPUs featuring RDNA4 boast significant efficiency improvements in ray tracing and machine learning, while also enhancing rasterization. Improvements include enhanced compression, a faster media engine (supporting H.264, H.265, and AV1 codecs with reduced latency), and an upgraded display engine (integrating Radeon Image Sharpening). RDNA4 excels in power consumption, particularly multi-monitor idle power. Further performance and efficiency gains come from an improved workgroup processor, larger L2 cache, and optimized Infinity Fabric architecture. In short, RDNA4 marks a significant leap in AMD's GPU design, prioritizing efficiency to deliver a more balanced and power-efficient experience for gamers and professionals alike.
Read more