Fonctions SIMD : La promesse et les dangers de l'auto-vectorisation du compilateur
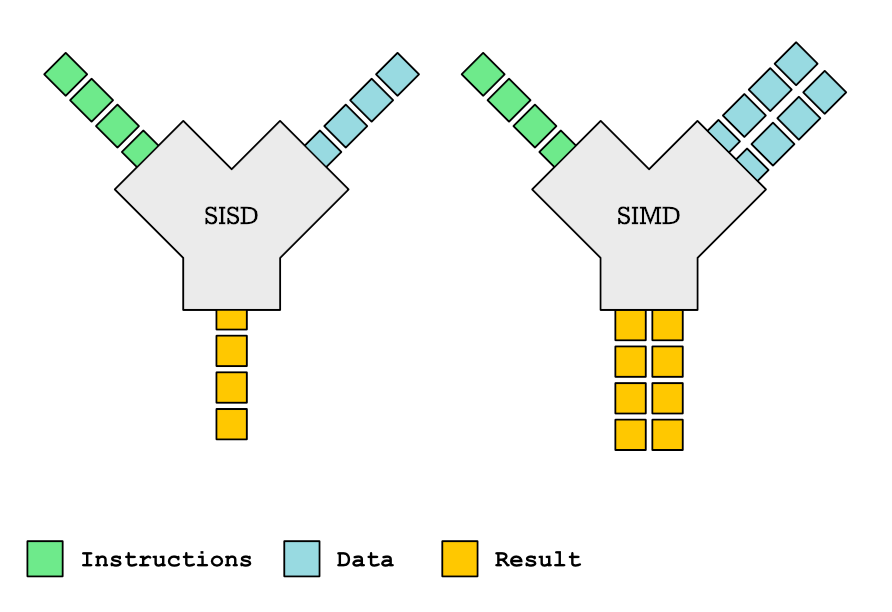
Cet article explore les complexités des fonctions SIMD et leur rôle dans l'auto-vectorisation du compilateur. Les fonctions SIMD, capables de traiter plusieurs données simultanément, offrent des améliorations significatives des performances. Cependant, la prise en charge des fonctions SIMD par le compilateur est inégale, et le code vectorisé généré peut être étonnamment inefficace. L'article détaille comment déclarer et définir des fonctions SIMD à l'aide de pragmas OpenMP et d'attributs spécifiques au compilateur, en analysant l'impact des différents types de paramètres (variable, uniforme, linéaire) sur l'efficacité de la vectorisation. Il traite également de la fourniture d'implémentations vectorisées personnalisées à l'aide d'intrinsèques, de la gestion de l'intégration des fonctions et de la navigation dans les particularités du compilateur. Bien qu'elles promettent des gains de performances, l'application pratique des fonctions SIMD présente des défis considérables.
Lire plus

