OpenAI publie gpt-oss : des LLMs puissants et open-weight exécutables localement
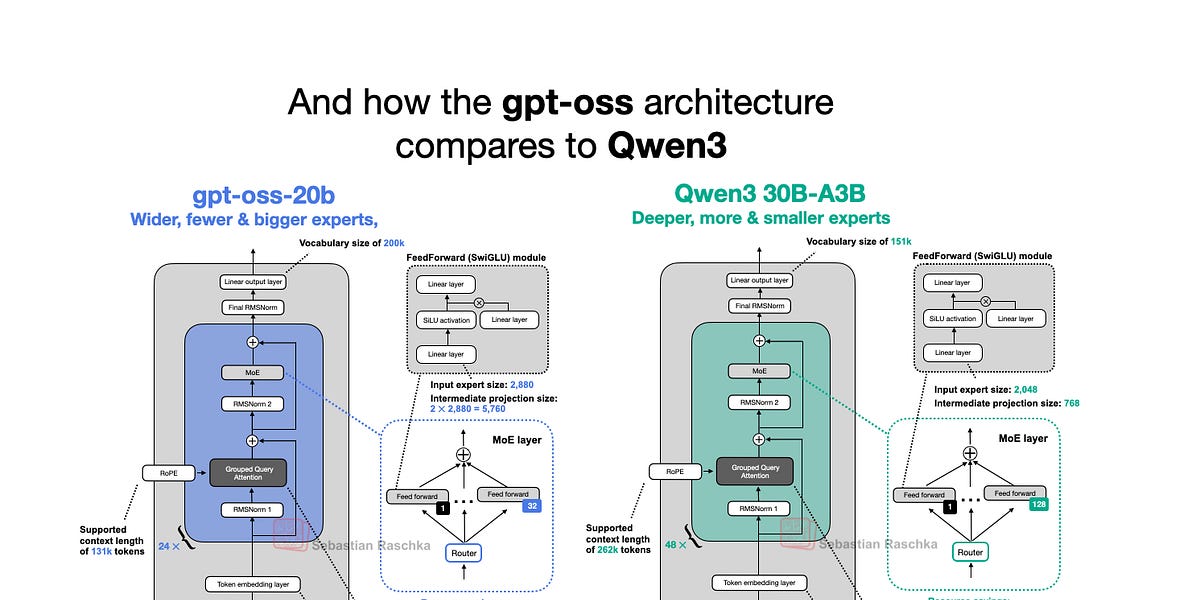
OpenAI a publié cette semaine ses nouveaux grands modèles de langage (LLM) à poids ouverts : gpt-oss-120b et gpt-oss-20b, ses premiers modèles à poids ouverts depuis GPT-2 en 2019. Étonnamment, grâce à des optimisations intelligentes, ils peuvent fonctionner localement. Cet article examine en détail l’architecture du modèle gpt-oss, en la comparant à des modèles tels que GPT-2 et Qwen3. Il souligne des choix architecturaux uniques, tels que Mixture-of-Experts (MoE), Grouped Query Attention (GQA) et l’attention à fenêtre glissante. Bien que les benchmarks montrent que gpt-oss offre des performances comparables à celles des modèles propriétaires dans certains domaines, sa capacité d’exécution locale et sa nature open-source en font un atout précieux pour la recherche et les applications.
Lire plus
