AMD RDNA3 GPUにおけるFP32行列乗算の最適化:rocBLASを60%上回る
2025-03-28
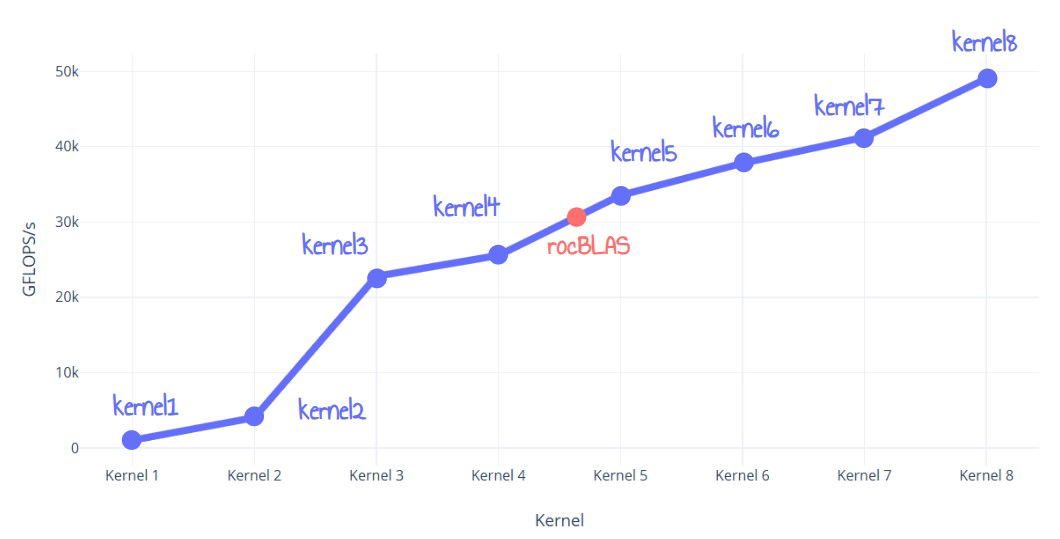
この記事では、AMD RDNA3 GPUでrocBLASを60%上回る性能のFP32行列乗算カーネルを作成する最適化の過程を詳しく説明しています。著者は、ナイーブな実装から始めて、ISAレベルの最適化へと段階的に8つのカーネルを改良しました。手法としては、LDSタイリング、レジスタタイリング、グローバルメモリダブルバッファリング、LDS利用率の最適化、そして最終的にはISAレベルでのVALU最適化とループアンローリングなどが含まれます。最終的なカーネルはrocBLASを上回り、約50TFLOPSを達成しました。
開発