Multiplicação de Matrizes FP32 otimizada em GPU AMD RDNA3: Superando o rocBLAS em 60%
2025-03-28
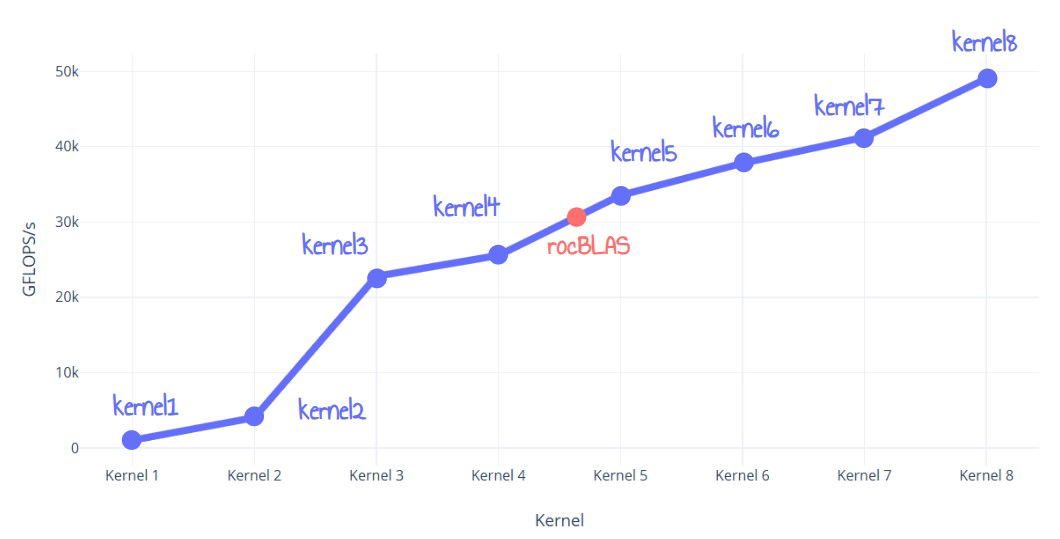
Este artigo descreve a jornada de otimização para criar um kernel de multiplicação de matrizes FP32 para GPUs AMD RDNA3 que supera o rocBLAS em 60%. O autor refina iterativamente oito kernels, começando com uma implementação ingênua e progredindo para otimizações em nível de ISA. As técnicas incluem tiling LDS, tiling de registradores, double buffering de memória global, otimização da utilização do LDS e, por fim, otimização da utilização do VALU em nível de ISA e desdobramento de loops. O kernel final supera o rocBLAS, atingindo quase 50 TFLOPS.
Desenvolvimento
multiplicação de matrizes