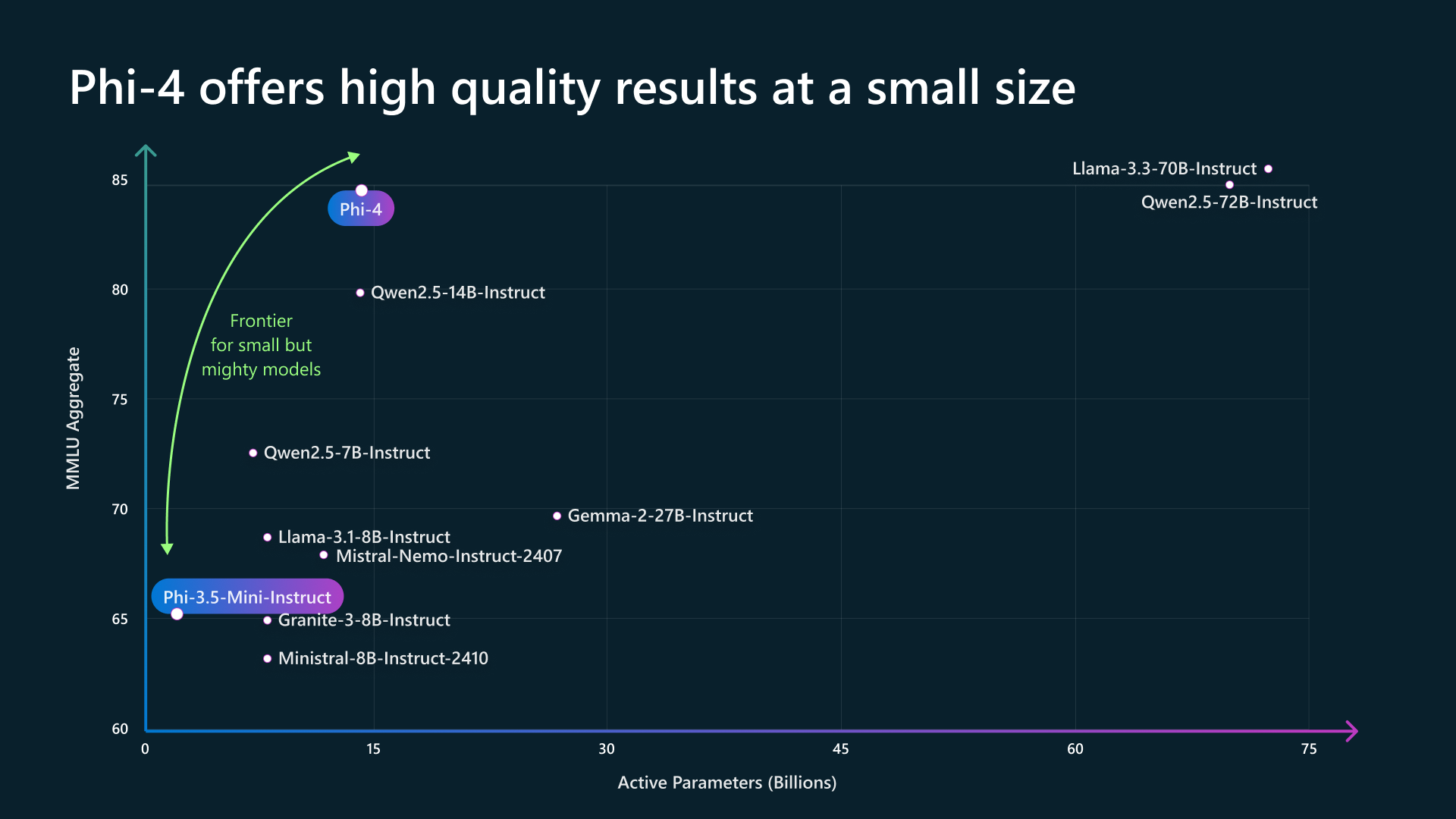
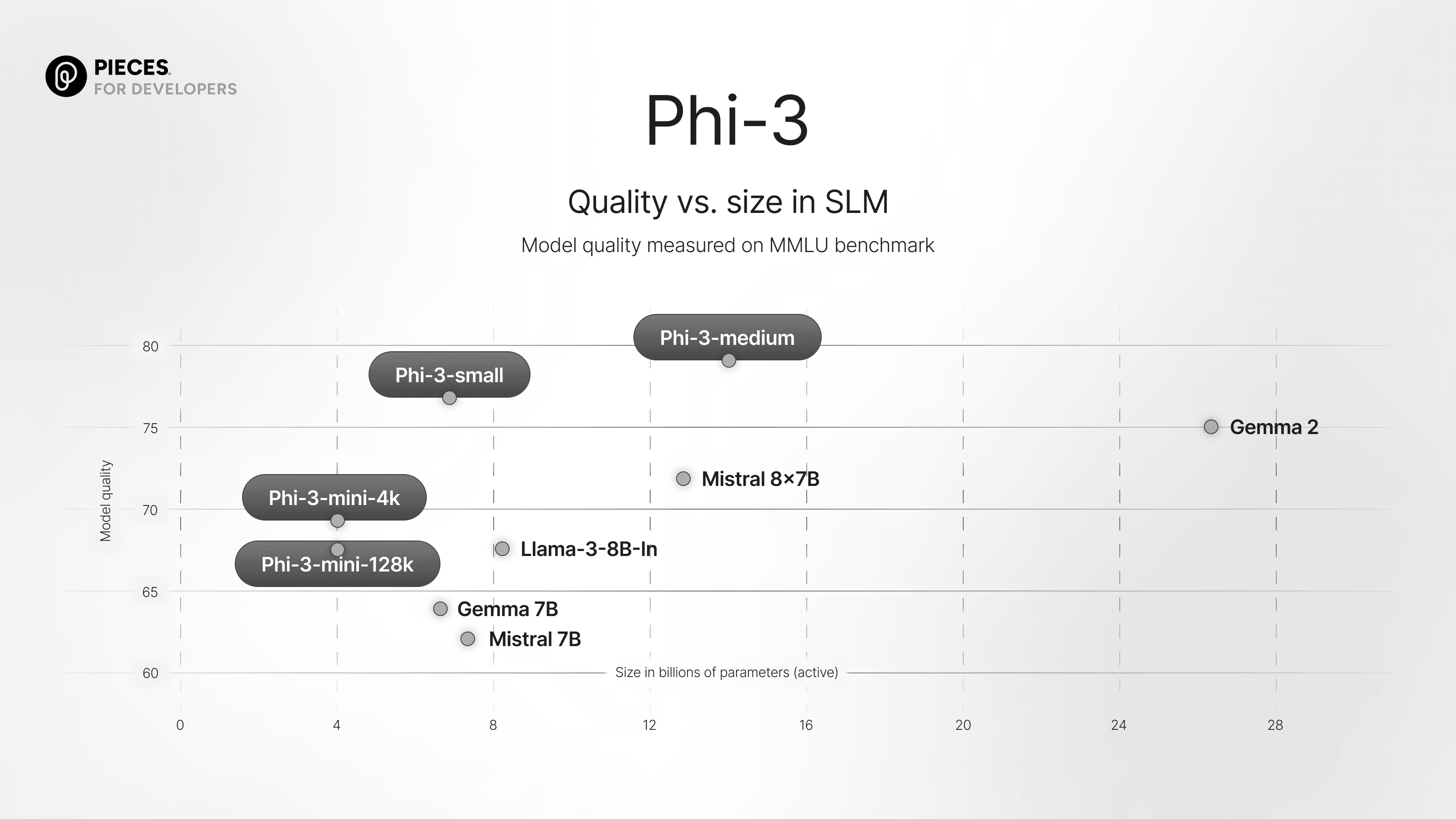
IA em sistemas operacionais: mais hype do que substância?

Microsoft, Apple e Google estão impulsionando agressivamente a integração de IA em seus sistemas operacionais, como o Copilot da Microsoft e o Apple Intelligence. No entanto, o artigo argumenta que isso é mais hype do que benefício prático. Os usuários preferem sistemas operacionais estáveis, privados e personalizáveis, sem bloatware desnecessário, anúncios ou recursos de IA invasivos. Embora assistentes de IA tenham valor em nichos específicos (como programação), forçar sua integração no sistema operacional sacrifica a experiência do usuário e facilita uma maior coleta de dados pelas empresas de tecnologia. O sistema operacional ideal é estável, privado, leve e personalizável, com ferramentas de IA oferecidas como aplicativos autônomos opcionais, não como funções principais do sistema operacional.
Leia mais