Aligning Polynomial Features with Data Distribution: The Attention-Alignment Problem in ML
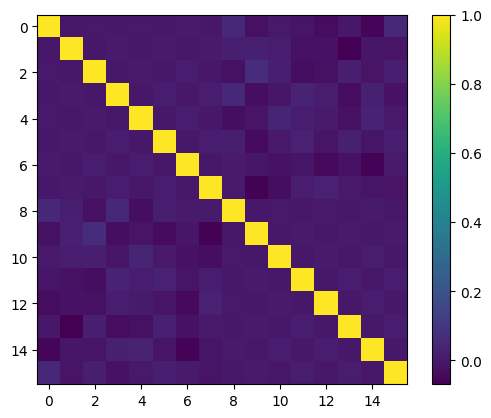
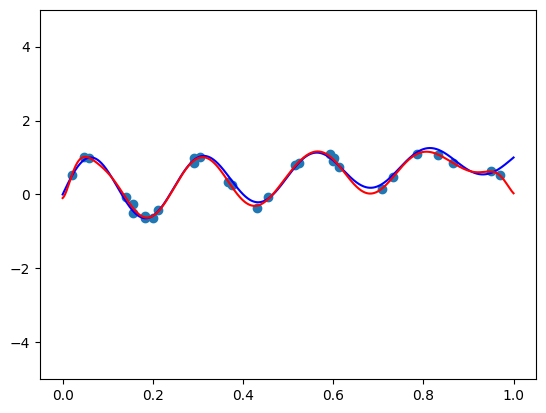
This post explores aligning polynomial features with data distribution for improved machine learning model performance. Orthogonal bases produce informative features when data is uniformly distributed, but real-world data isn't. Two approaches are presented: a mapping trick, transforming data to a uniform distribution before applying an orthogonal basis; and multiplying by a carefully chosen function to adjust the orthogonal basis's weight function to align with the data distribution. The first is more practical, achievable with Scikit-Learn's QuantileTransformer. The second is more complex, requiring deeper mathematical understanding and fine-tuning. Experiments on the California housing dataset show that near-orthogonal features from the first method outperform traditional min-max scaling in linear regression.
Read more