Beyond BPE: The Future of Tokenization in Large Language Models
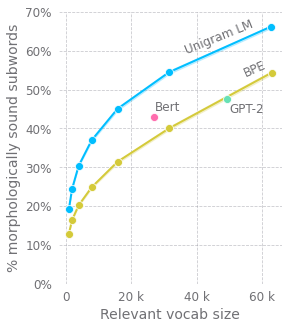
This article explores improvements to tokenization methods in large pre-trained language models. The author questions the commonly used Byte Pair Encoding (BPE) method, highlighting its shortcomings in handling subwords at the beginning and inside words. Alternatives are suggested, such as adding a new word mask. Furthermore, the author argues against using compression algorithms for preprocessing inputs, advocating for character-level language modeling, drawing parallels with Recurrent Neural Networks (RNNs) and deeper self-attention models. However, the quadratic complexity of the attention mechanism presents a challenge. The author proposes a tree-structure-based approach, using windowed subsequences and hierarchical attention to reduce computational complexity while better capturing language structure.
Read more