Unlocking Tabular Data for LLMs: A Mechanical Distillation Approach
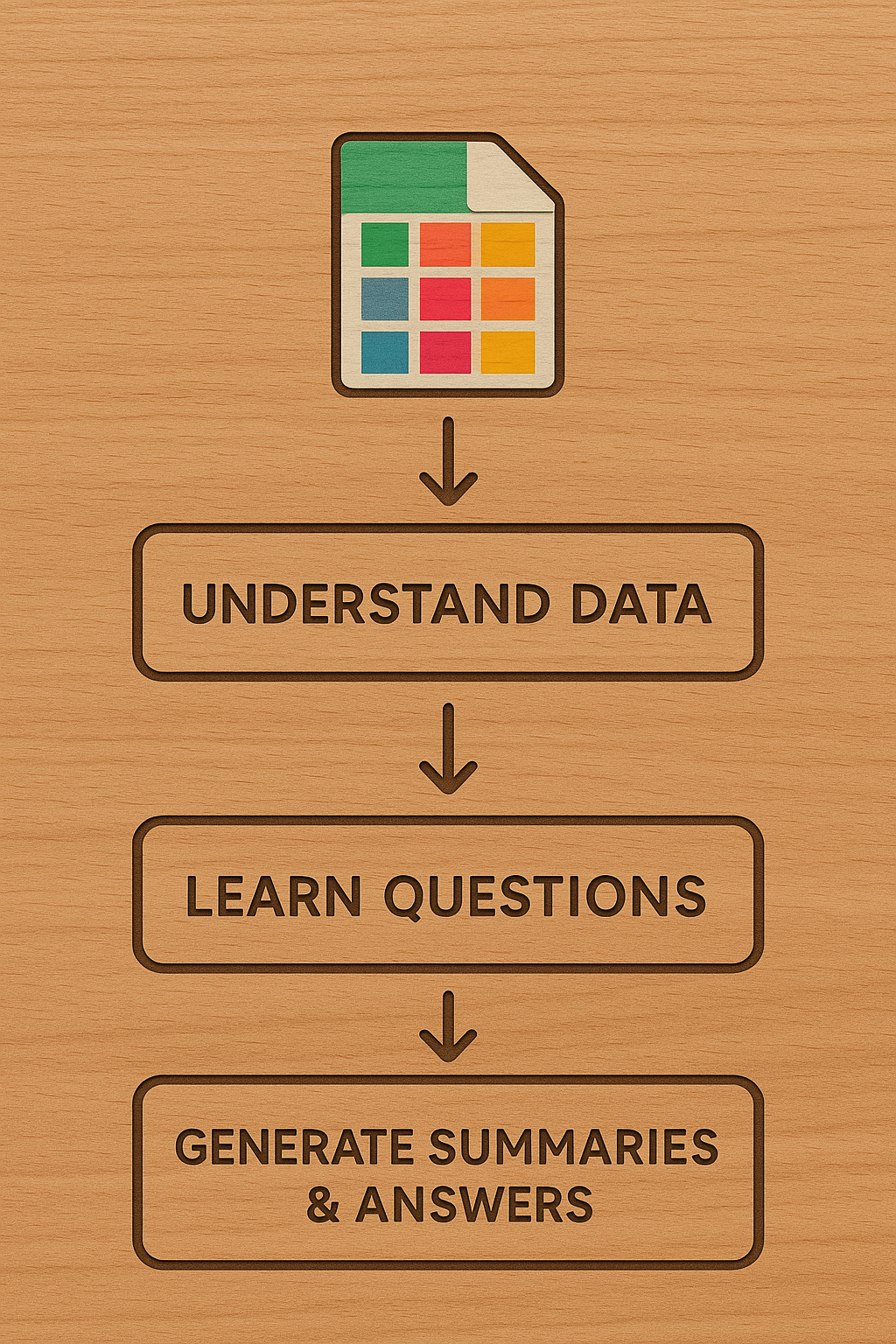
Large language models (LLMs) excel at processing text and images, but struggle with tabular data. Currently, LLMs primarily rely on published statistical summaries, failing to fully leverage the knowledge within tabular datasets like survey data. This article proposes a novel approach using mechanical distillation techniques to create univariate, bivariate, and multivariate summaries. This is augmented by prompting the LLM to suggest relevant questions and learn from the data. The three-step pipeline involves understanding data structure, identifying question types, and generating mechanical summaries and visualizations. The authors suggest this approach can enhance Retrieval Augmented Generation (RAG) systems and supplement potentially biased 'world knowledge', recommending starting with scientific paper repositories (like Harvard Dataverse) and administrative data for validation.