Desbloqueando Dados Tabulares para LLMs: Uma Abordagem de Destilação Mecânica
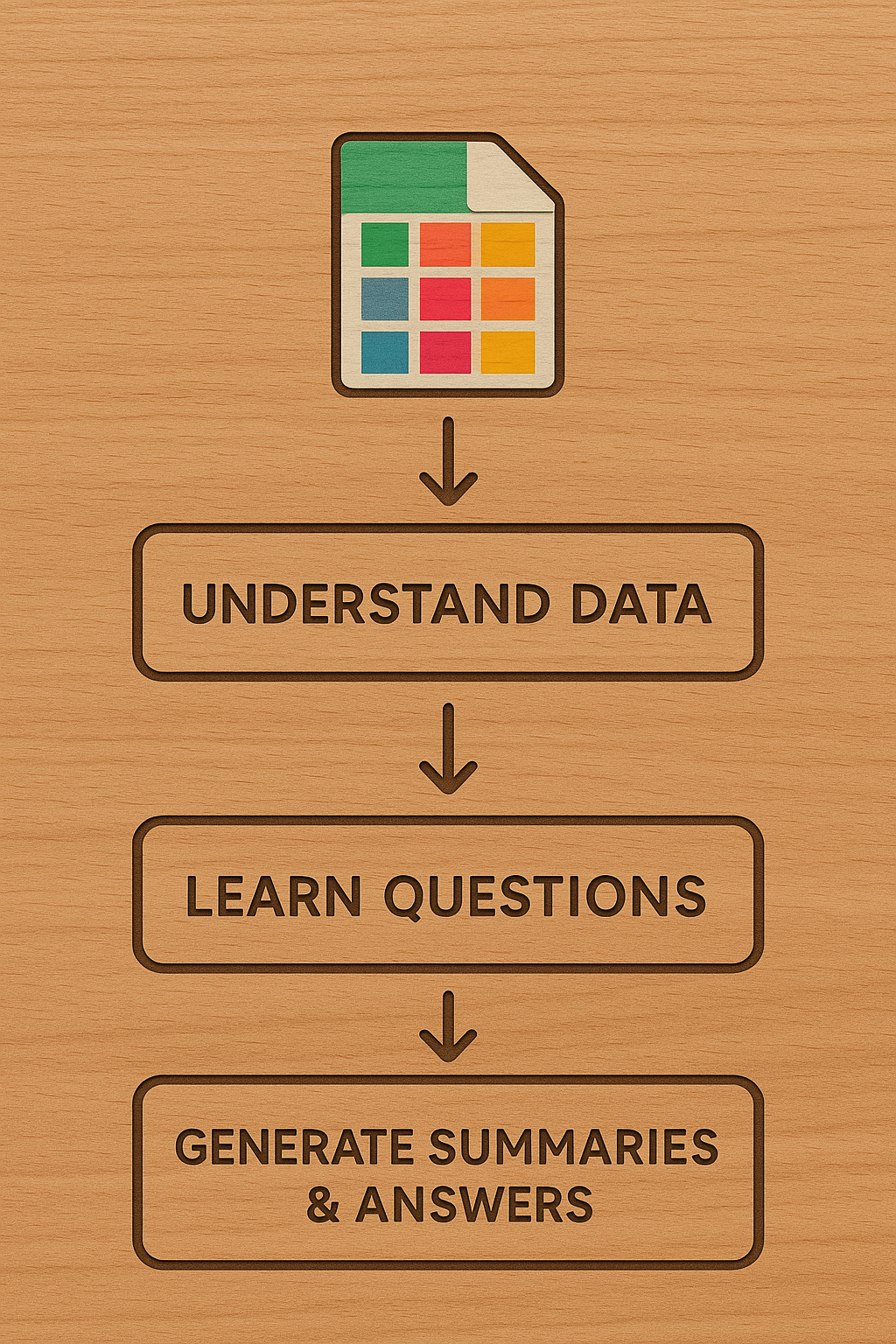
Os grandes modelos de linguagem (LLMs) são excelentes no processamento de texto e imagens, mas têm dificuldades com dados tabulares. Atualmente, os LLMs dependem principalmente de resumos estatísticos publicados, deixando de aproveitar totalmente o conhecimento contido em conjuntos de dados tabulares, como dados de pesquisas. Este artigo propõe uma nova abordagem usando técnicas de destilação mecânica para criar resumos univariados, bivariados e multivariados. Isso é aumentado solicitando ao LLM que sugira perguntas relevantes e aprenda com os dados. O pipeline de três etapas envolve a compreensão da estrutura de dados, a identificação dos tipos de perguntas e a geração de resumos mecânicos e visualizações. Os autores sugerem que esta abordagem pode melhorar os sistemas de Geração Aumentada por Recuperação (RAG) e complementar o 'conhecimento do mundo' potencialmente tendencioso, recomendando começar com repositórios de artigos científicos (como o Harvard Dataverse) e dados administrativos para validação.