Desbloqueo de datos tabulares para LLMs: Un enfoque de destilación mecánica
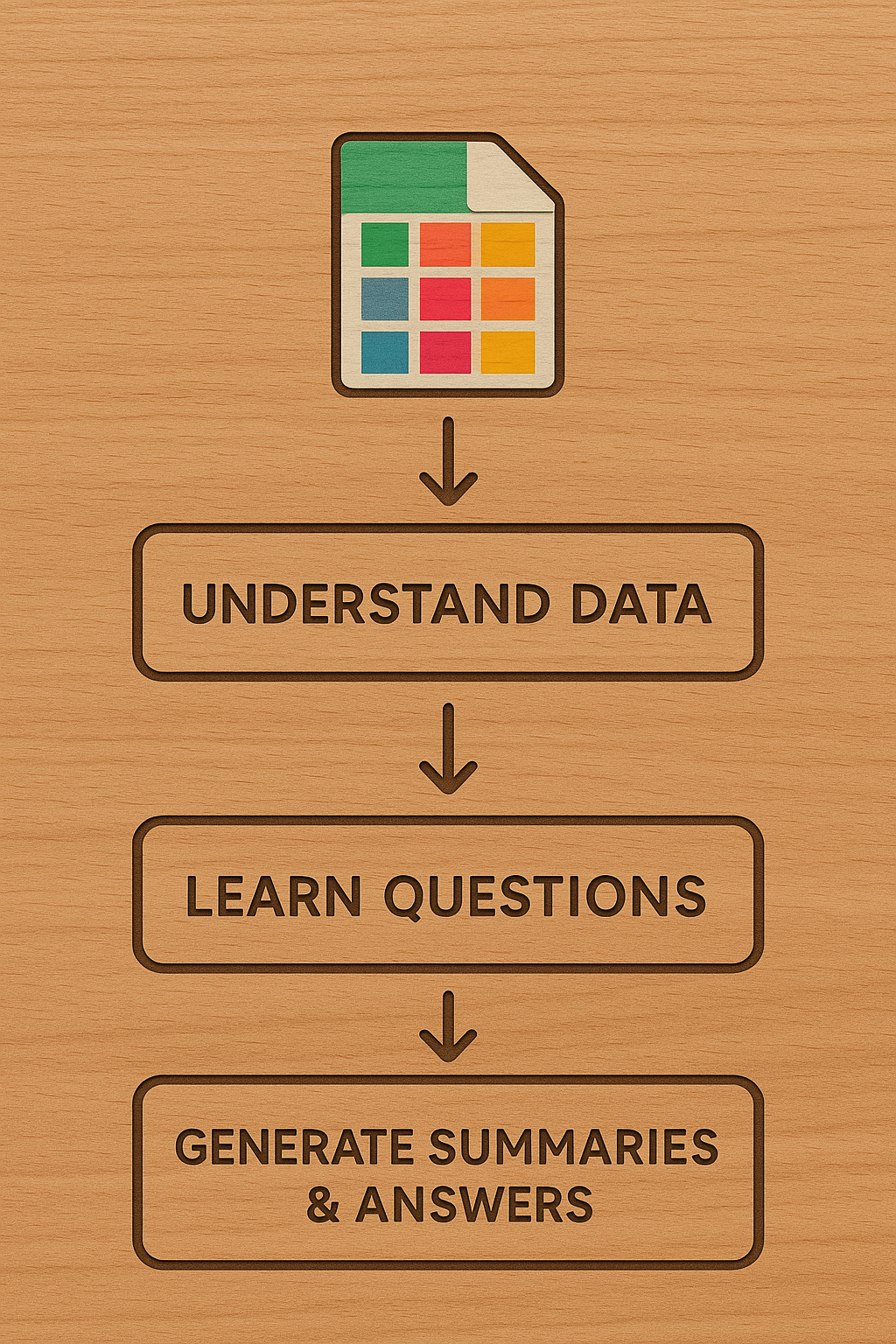
Los grandes modelos de lenguaje (LLM) sobresalen en el procesamiento de texto e imágenes, pero tienen dificultades con los datos tabulares. Actualmente, los LLM dependen principalmente de resúmenes estadísticos publicados, dejando de aprovechar completamente el conocimiento contenido en conjuntos de datos tabulares, como los datos de encuestas. Este artículo propone un nuevo enfoque que utiliza técnicas de destilación mecánica para crear resúmenes univariados, bivariados y multivariados. Esto se complementa solicitando al LLM que sugiera preguntas relevantes y aprenda de los datos. El pipeline de tres etapas implica comprender la estructura de datos, identificar los tipos de preguntas y generar resúmenes mecánicos y visualizaciones. Los autores sugieren que este enfoque puede mejorar los sistemas de Generación Aumentada por Recuperación (RAG) y complementar el 'conocimiento del mundo' potencialmente sesgado, recomendando comenzar con repositorios de artículos científicos (como Harvard Dataverse) y datos administrativos para la validación.