Mirage Persistent Kernel : Compilation des LLMs en un seul mégakernel pour une inférence ultrarapide
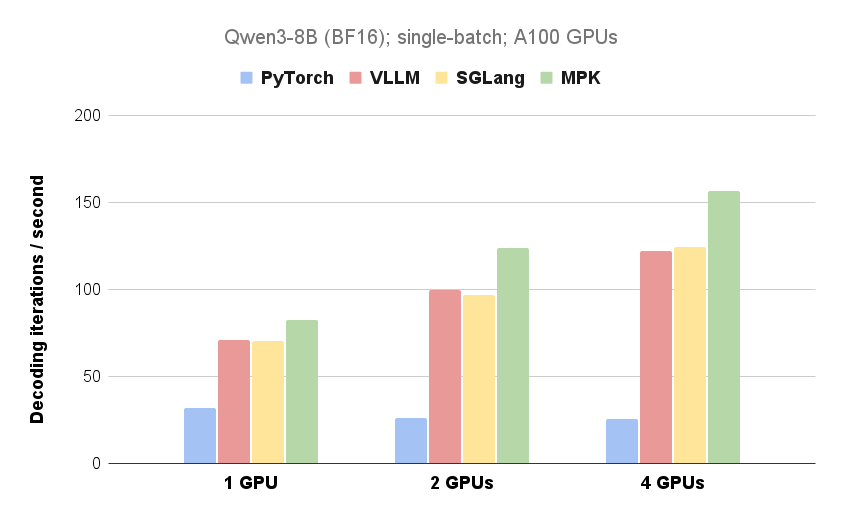
Des chercheurs de la CMU, de l'UW, de Berkeley, de NVIDIA et de Tsinghua ont développé Mirage Persistent Kernel (MPK), un compilateur et un système d'exécution qui transforme automatiquement l'inférence des grands modèles de langage (LLM) sur plusieurs GPU en un mégakernel hautes performances. En fusionnant tous les calculs et les communications en un seul noyau, MPK élimine la surcharge de lancement du noyau, superpose les calculs et les communications et réduit considérablement la latence d'inférence du LLM. Les expériences montrent des améliorations de performances substantielles sur les configurations mono-GPU et multi-GPU, avec des gains plus importants dans les environnements multi-GPU. Les travaux futurs se concentrent sur l'extension de MPK pour prendre en charge les architectures GPU de nouvelle génération et gérer les charges de travail dynamiques.