大型语言模型不再是“互联网训练”的产物
2024-06-01
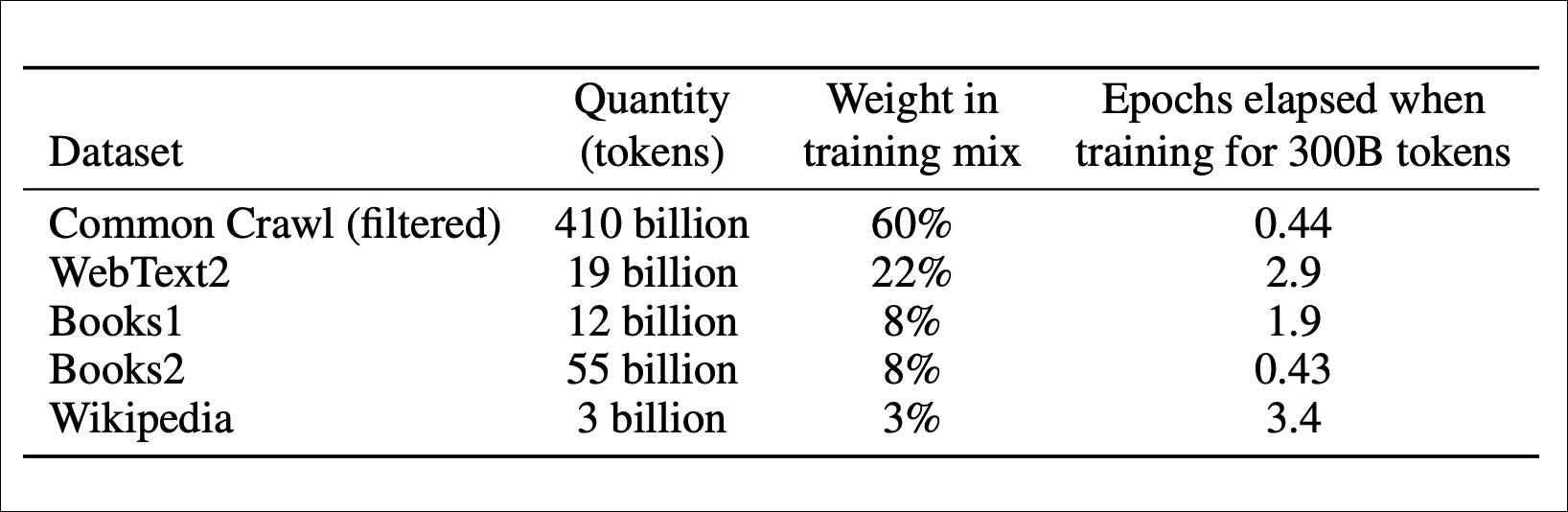
过去,大型语言模型主要依赖互联网数据进行训练,导致其在生成较少见的网络内容方面表现不佳。然而,随着技术的进步,以及研究人员意识到仅仅依靠互联网数据存在的局限性,越来越多的非公开数据和人工创建的数据被用于训练大型语言模型。例如,通过人工标注、强化学习、收集用户使用数据以及购买专业领域数据等方式,可以有效提升模型的性能。未来,随着对定制化训练数据的投入不断加大,大型语言模型将超越“互联网模拟器”,在生成更复杂、更具专业性的内容方面取得突破。
56
未分类
数据训练