Word2Vec's Secret Sauce: Bridging Traditional and Neural Methods
2025-02-17
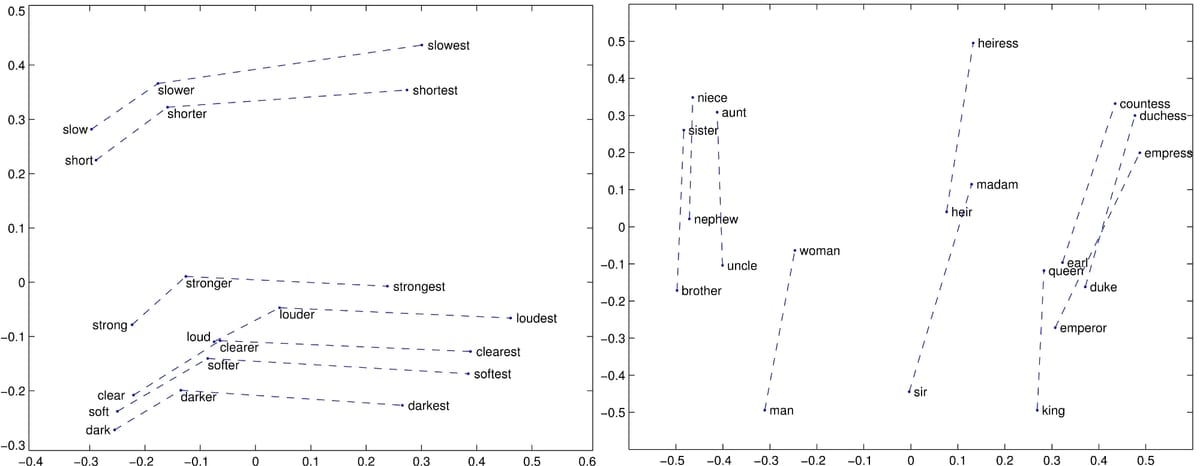
This blog post delves into the factors contributing to Word2Vec's success and its relationship with traditional word embedding models. By comparing models like GloVe, SVD, Skip-gram with Negative Sampling (SGNS), and PPMI, the author reveals that hyperparameter tuning is often more crucial than algorithm choice. The research demonstrates that traditional distributional semantic models (DSMs), with proper pre- and post-processing, can achieve performance comparable to neural network models. The article highlights the benefits of combining traditional and neural approaches, offering a fresh perspective on word embedding learning.