Optimized FP32 Matrix Multiplication on AMD RDNA3 GPU: Outperforming rocBLAS by 60%
2025-03-28
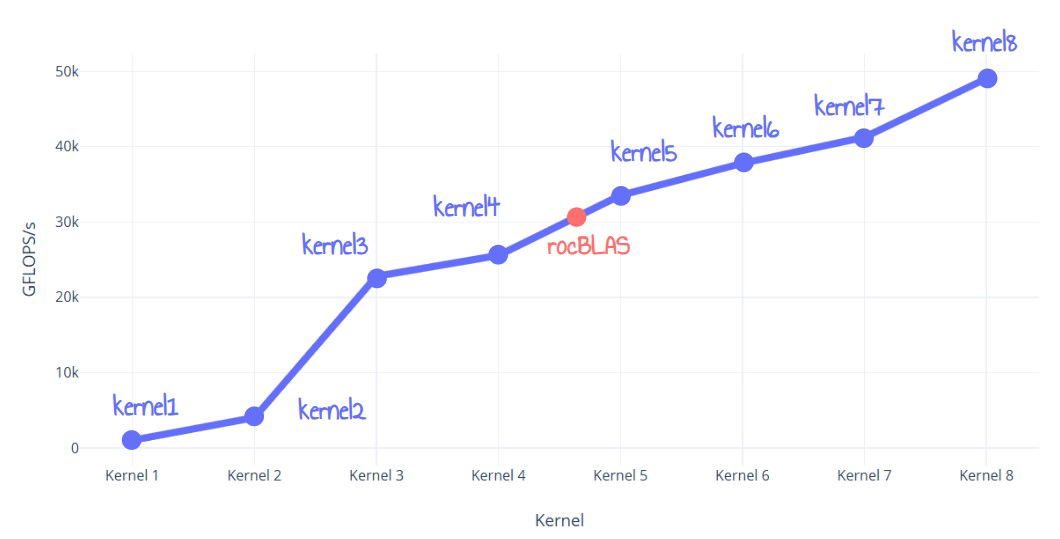
This post details the optimization journey of creating an FP32 matrix multiplication kernel for AMD RDNA3 GPUs that surpasses rocBLAS by 60%. The author iteratively refines eight kernels, starting with a naive implementation and progressing to ISA-level optimizations. Techniques include LDS tiling, register tiling, global memory double buffering, LDS utilization optimization, and ultimately ISA-level VALU optimization and loop unrolling. The final kernel outperforms rocBLAS, achieving nearly 50 TFLOPS.
Development
matrix multiplication