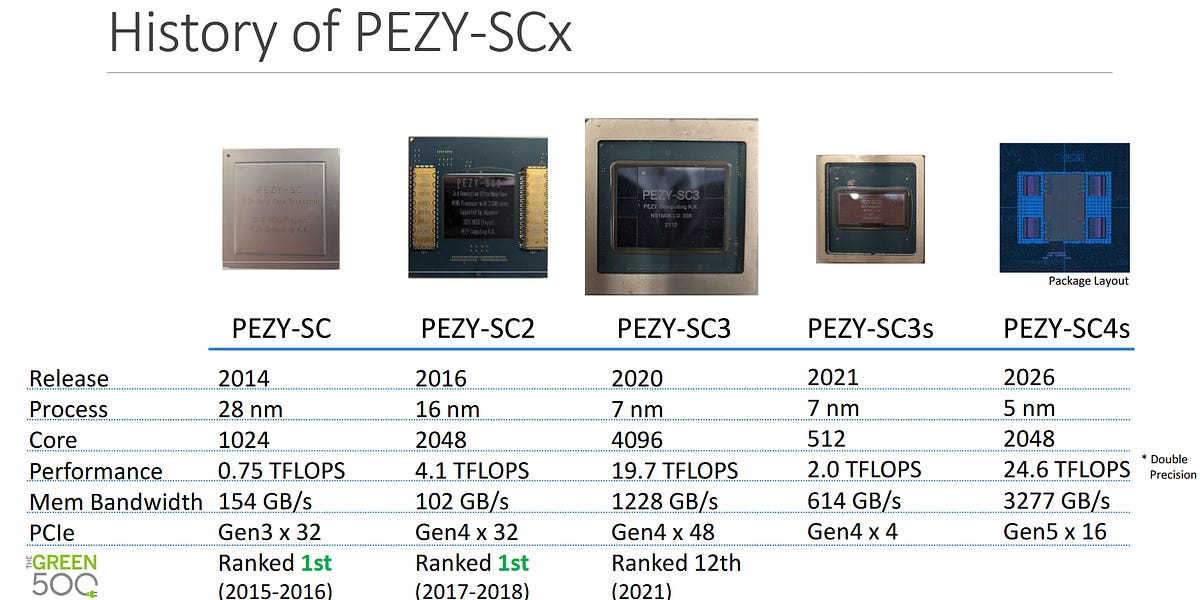
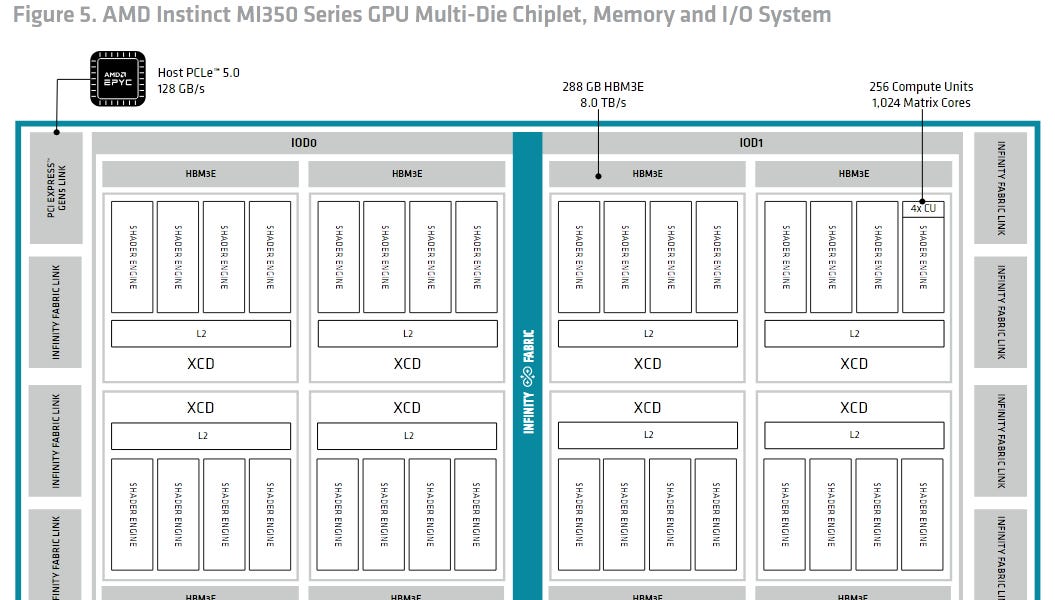
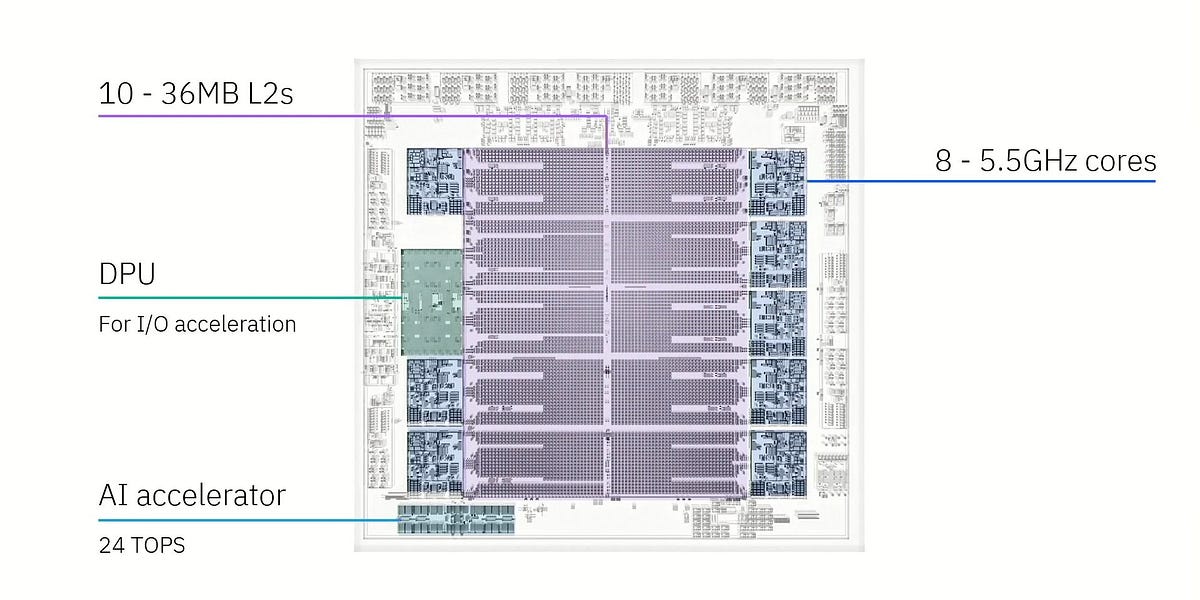
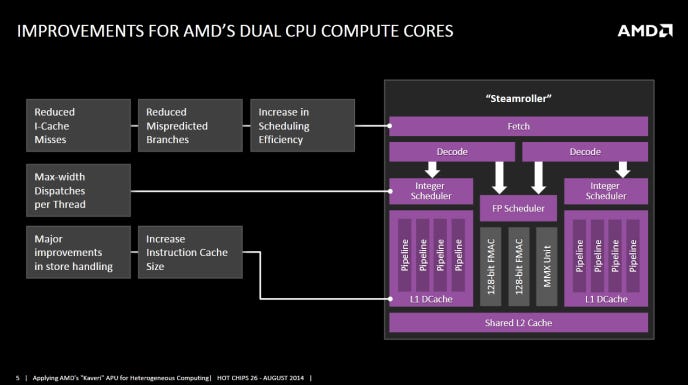
AMD RDNA4 : L'efficacité au cœur de la nouvelle architecture GPU

La dernière architecture RDNA4 d'AMD privilégie l'efficacité au rendement brut. Les GPU de la série RX 9000 intégrant RDNA4 offrent des améliorations significatives de l'efficacité en ray tracing et en apprentissage automatique, tout en améliorant la rastérisation. Les améliorations incluent une compression optimisée, un moteur multimédia plus rapide (compatible avec les codecs H.264, H.265 et AV1 à faible latence) et un moteur d'affichage mis à jour (intégrant le filtre de netteté Radeon Image Sharpening). RDNA4 excelle en termes de consommation d'énergie, notamment en veille sur plusieurs moniteurs. Des gains supplémentaires de performances et d'efficacité proviennent d'un processeur de groupe de travail amélioré, d'un cache L2 plus grand et d'une architecture Infinity Fabric optimisée. En résumé, RDNA4 marque un progrès significatif dans la conception des GPU AMD, en donnant la priorité à l'efficacité pour offrir une expérience plus équilibrée et économe en énergie aux joueurs et aux professionnels.
Lire plus