多項式特徴量とデータ分布の整合: MLにおける注意-整合問題
2025-08-26
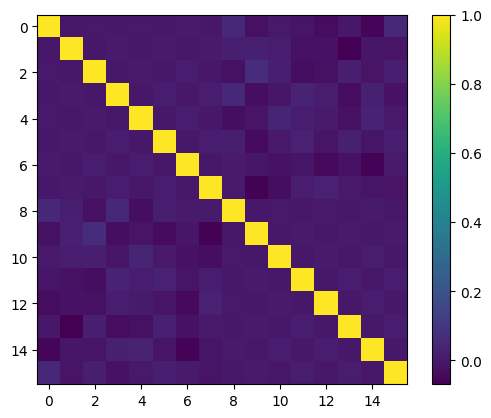
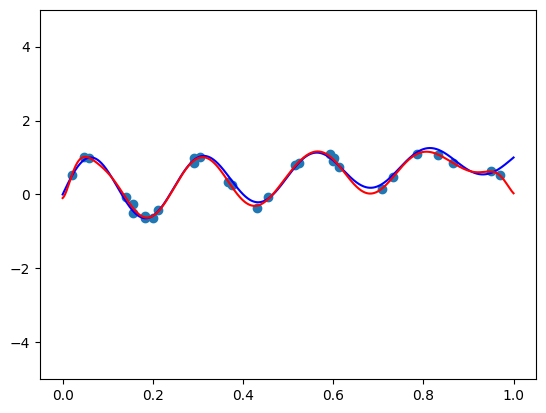
この記事では、機械学習モデルの性能向上のため、多項式特徴量とデータ分布の整合について探求します。直交基底は、データが一様に分布している場合、情報量の多い特徴量を生成しますが、現実世界のデータはそうではありません。2つのアプローチが提示されています。1つは、直交基底を適用する前にデータを一様分布に変換するマッピングの手法です。もう1つは、注意深く選択された関数をかけることで、直交基底の重み関数を調整し、データ分布に合わせることです。前者はScikit-LearnのQuantileTransformerで実現できる、より実際的な方法です。後者はより複雑で、深い数学的理解と微調整が必要です。カリフォルニア住宅データセットの実験では、前者の方法で生成された準直交特徴量が、従来の最小-最大スケーリングよりも線形回帰で優れた性能を示しました。
続きを読む