Mirage Persistent Kernel:超高速推論のためのLLMを単一メガカーネルにコンパイル
2025-06-19
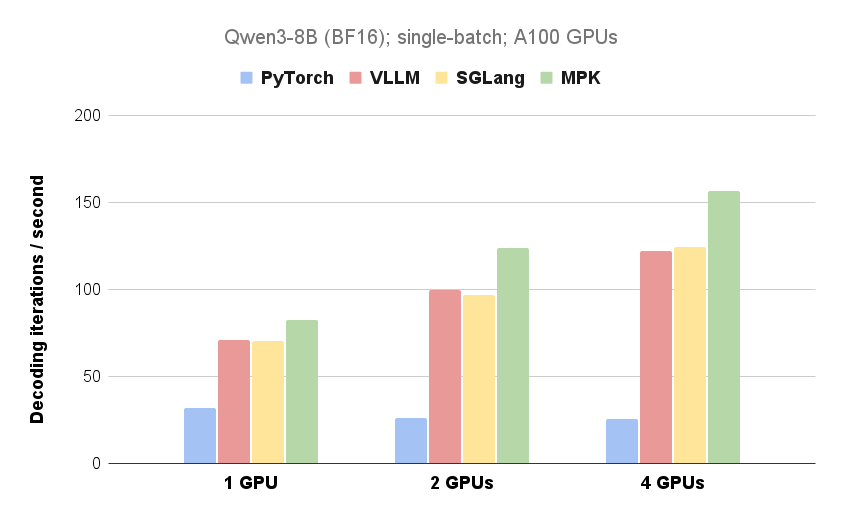
CMU、UW、バークレー、NVIDIA、清華大学の研究者らが、Mirage Persistent Kernel(MPK)を開発しました。これは、マルチGPU大規模言語モデル(LLM)の推論を、高性能なメガカーネルに自動的に変換するコンパイラとランタイムシステムです。すべての計算と通信を単一のカーネルに融合させることで、MPKはカーネル起動オーバーヘッドを排除し、計算と通信をオーバーラップさせることで、LLM推論のレイテンシを大幅に削減します。実験により、シングルGPUとマルチGPUの両方の構成において、顕著な性能向上を示し、特にマルチGPU環境でその利点が際立ちます。今後の研究では、次世代GPUアーキテクチャのサポートと、動的なワークロードの処理に焦点を当てています。
続きを読む
AI
メガカーネル