Alinhando recursos polinomiais com a distribuição de dados: O problema de atenção-alinhamento em ML
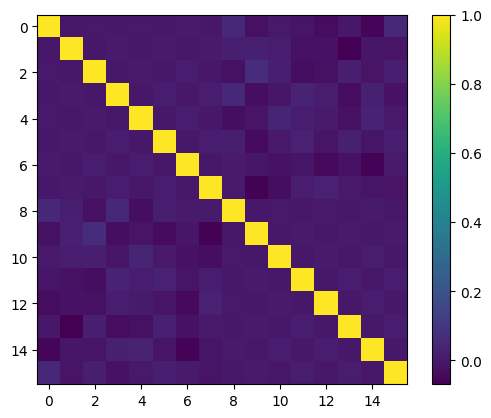
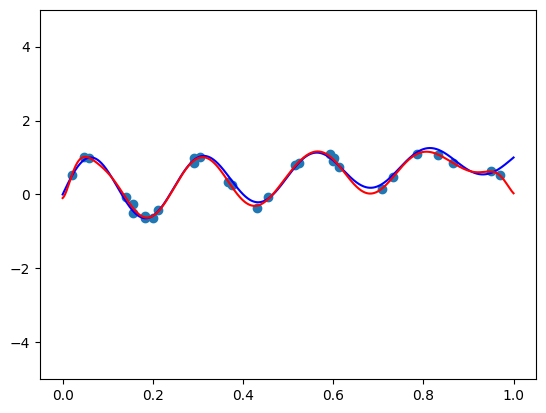
Esta publicação explora o alinhamento de recursos polinomiais com a distribuição de dados para melhorar o desempenho do modelo de aprendizado de máquina. Bases ortogonais produzem recursos informativos quando os dados são distribuídos uniformemente, mas os dados do mundo real não são. Duas abordagens são apresentadas: um truque de mapeamento, transformando dados em uma distribuição uniforme antes de aplicar uma base ortogonal; e multiplicando por uma função cuidadosamente escolhida para ajustar a função de peso da base ortogonal para se alinhar com a distribuição de dados. A primeira é mais prática, atingível com o QuantileTransformer do Scikit-Learn. A segunda é mais complexa, exigindo um conhecimento matemático mais profundo e ajustes finos. Experimentos no conjunto de dados de moradias da Califórnia mostram que recursos quase ortogonais do primeiro método superam o dimensionamento mínimo-máximo tradicional na regressão linear.
Leia mais