Funções SIMD: A promessa e o perigo da autovetorização do compilador
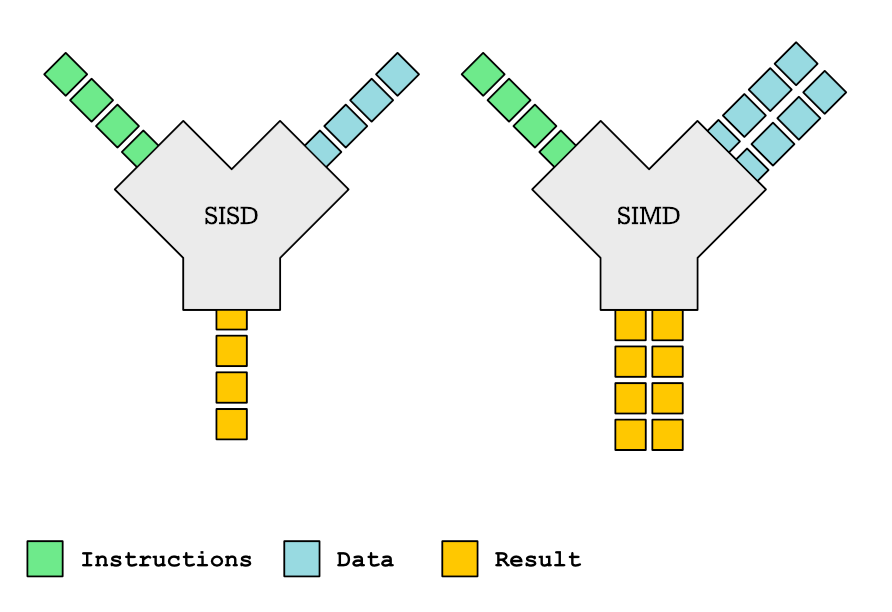
Este artigo mergulha nas complexidades das funções SIMD e seu papel na autovetorização do compilador. As funções SIMD, capazes de processar múltiplos pontos de dados simultaneamente, oferecem melhorias significativas de desempenho. No entanto, o suporte do compilador para funções SIMD é irregular, e o código vetorial gerado pode ser surpreendentemente ineficiente. O artigo detalha como declarar e definir funções SIMD usando pragmas OpenMP e atributos específicos do compilador, analisando o impacto de diferentes tipos de parâmetros (variável, uniforme, linear) na eficiência da vetorização. Também abrange a provisão de implementações vetorializadas personalizadas usando intrínsecos, o tratamento de inlining de funções e a navegação por peculiaridades do compilador. Embora prometendo ganhos de desempenho, a aplicação prática de funções SIMD apresenta desafios consideráveis.
Leia mais

