OpenAI lança LLMs gpt-oss: modelos poderosos e de código aberto que rodam localmente
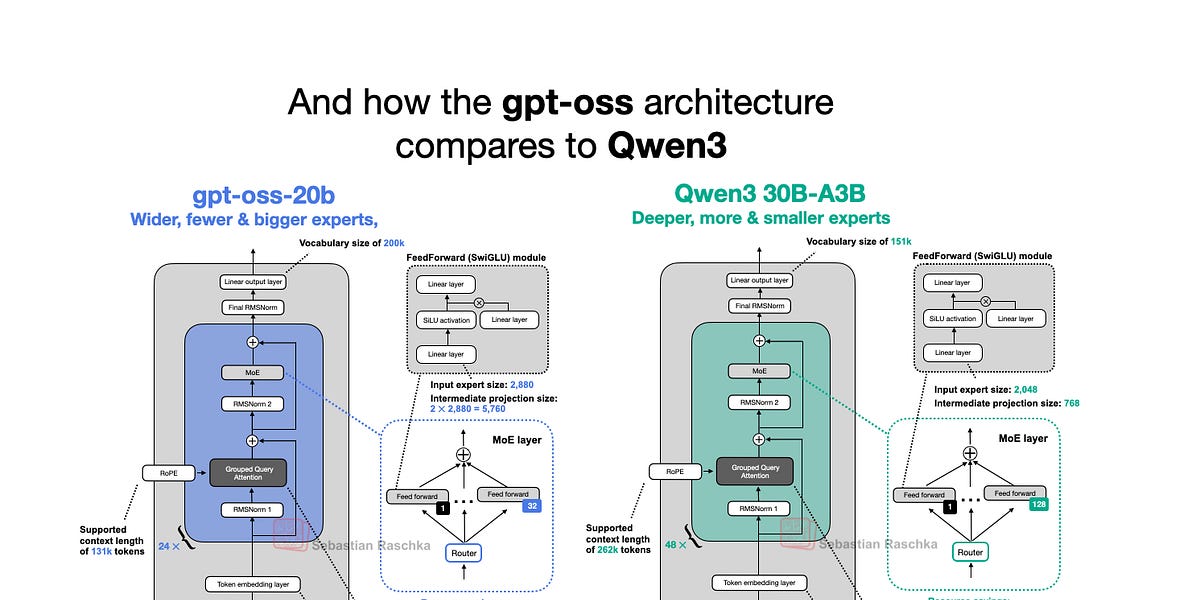
A OpenAI lançou nesta semana os novos modelos de linguagem grandes (LLMs) de peso aberto: gpt-oss-120b e gpt-oss-20b, seus primeiros modelos de peso aberto desde o GPT-2 em 2019. Surpreendentemente, graças a otimizações inteligentes, eles podem ser executados localmente. Este artigo mergulha na arquitetura do modelo gpt-oss, comparando-o com modelos como GPT-2 e Qwen3. Ele destaca escolhas arquitetônicas exclusivas, como Mixture-of-Experts (MoE), Grouped Query Attention (GQA) e atenção com janela deslizante. Embora os benchmarks mostrem o gpt-oss tendo desempenho comparável a modelos de código fechado em algumas áreas, sua capacidade de execução local e natureza de código aberto o tornam um ativo valioso para pesquisa e aplicações.
Leia mais
