Cerebras Lança Planos de Codificação de IA Ultra-Rápidos: Pro e Max
2025-08-02

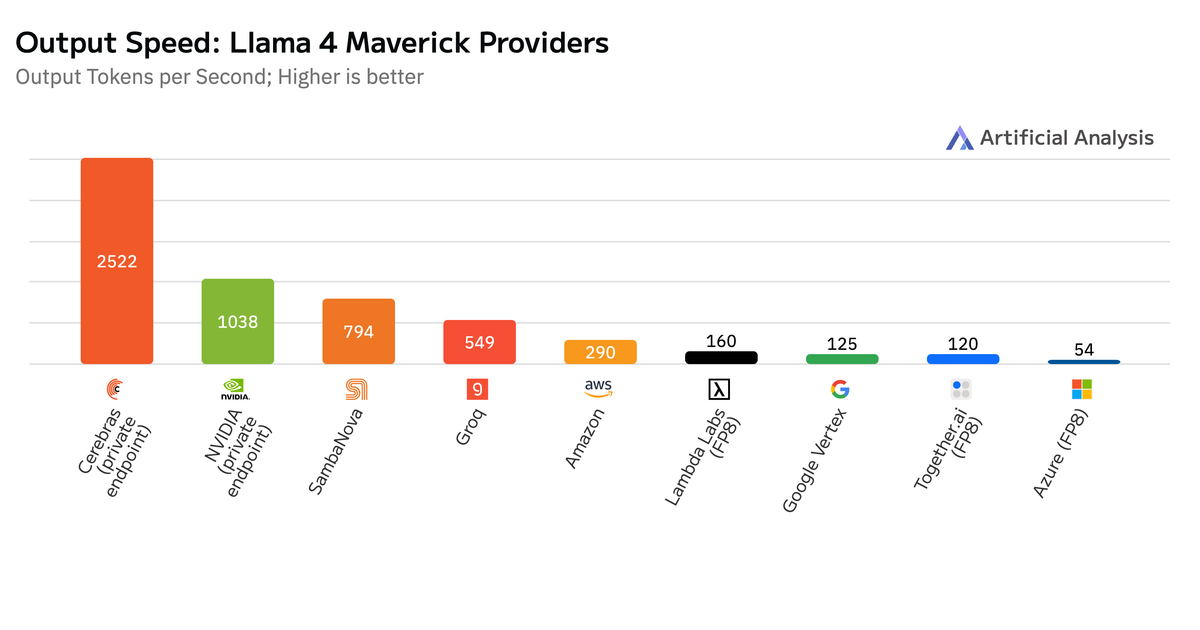
A Cerebras apresenta dois novos planos de codificação de IA: Code Pro (US$ 50/mês) e Code Max (US$ 200/mês), ambos alimentados pelo Qwen3-Coder da Alibaba, um modelo de codificação de peso aberto líder. Com velocidades de até 2.000 tokens por segundo, uma janela de contexto de 131.000 tokens e sem bloqueio de IDE proprietária ou limites semanais, ele oferece geração de código instantânea. Os usuários podem integrar-se aos seus IDEs de IA preferidos para um fluxo de trabalho contínuo. O Code Pro é ideal para desenvolvedores independentes e projetos menores, enquanto o Code Max atende às necessidades de desenvolvedores em tempo integral com alto volume.
Leia mais
Desenvolvimento