O Segredo do Word2Vec: Conectando Métodos Tradicionais e Neurais
2025-02-17
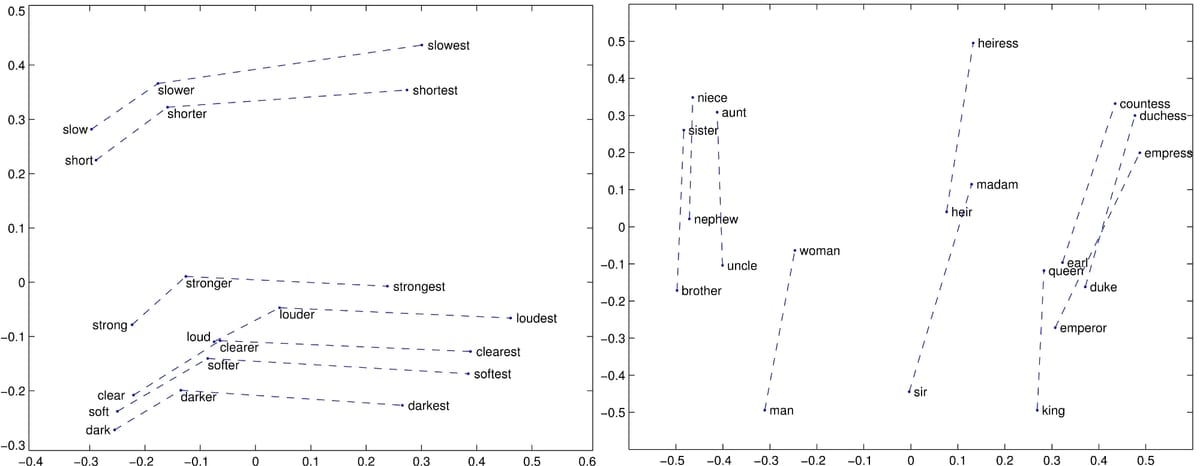
Este post de blog investiga os fatores que contribuem para o sucesso do Word2Vec e sua relação com modelos tradicionais de embedding de palavras. Comparando modelos como GloVe, SVD, Skip-gram with Negative Sampling (SGNS) e PPMI, o autor revela que a otimização de hiperparâmetros geralmente é mais crucial do que a escolha do algoritmo. A pesquisa demonstra que modelos semânticos distribucionais tradicionais (DSMs), com pré e pós-processamento adequados, podem alcançar desempenho comparável a modelos de redes neurais. O artigo destaca os benefícios da combinação de métodos tradicionais e neurais, oferecendo uma nova perspectiva para a aprendizagem de embedding de palavras.
Leia mais