Mirage Persistent Kernel: Compilando LLMs em um único megakernel para inferência ultrarrápida
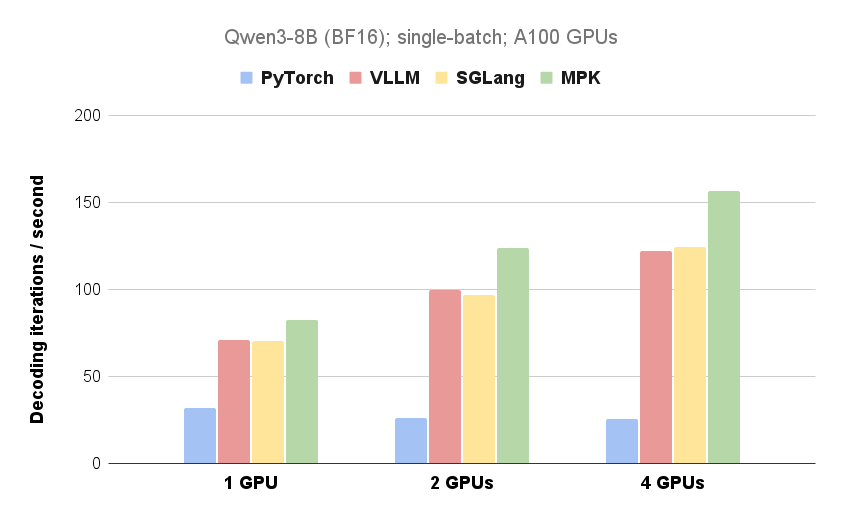
Pesquisadores da CMU, UW, Berkeley, NVIDIA e Tsinghua desenvolveram o Mirage Persistent Kernel (MPK), um compilador e sistema de runtime que transforma automaticamente a inferência de modelos de linguagem grandes (LLMs) em várias GPUs em um megakernel de alto desempenho. Ao fundir toda a computação e comunicação em um único kernel, o MPK elimina a sobrecarga de lançamento do kernel, sobrepõe computação e comunicação e reduz significativamente a latência de inferência do LLM. Experimentos demonstram melhorias de desempenho substanciais em configurações de GPU única e várias GPUs, com ganhos mais pronunciados em cenários de várias GPUs. O trabalho futuro se concentra em expandir o MPK para suportar arquiteturas de GPU de próxima geração e lidar com cargas de trabalho dinâmicas.
Leia mais