Au-delà de BPE : l’avenir de la tokenisation dans les grands modèles de langage
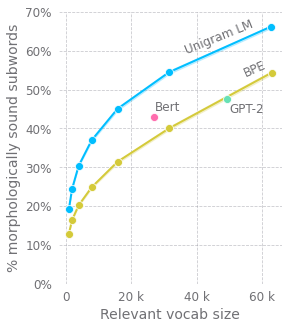
Cet article explore les améliorations apportées aux méthodes de tokenisation dans les grands modèles de langage pré-entraînés. L’auteur remet en question la méthode couramment utilisée de codage par paires de bytes (BPE), en soulignant ses lacunes dans le traitement des sous-mots au début et à l’intérieur des mots. Des alternatives sont suggérées, telles que l’ajout d’un masque de nouveau mot. En outre, l’auteur plaide contre l’utilisation d’algorithmes de compression pour le prétraitement des entrées, préconisant la modélisation du langage au niveau des caractères, en établissant des parallèles avec les réseaux neuronaux récurrents (RNN) et les modèles d’auto-attention plus profonds. Cependant, la complexité quadratique du mécanisme d’attention représente un défi. L’auteur propose une approche basée sur la structure arborescente, utilisant des sous-séquences fenêtrées et une attention hiérarchique pour réduire la complexité de calcul tout en capturant mieux la structure du langage.